83. Визуализация данных - Grafana
Содержание
Визуализация данных - Grafana
Мы много говорили о Kibana в этом разделе, посвященном Observability. Но мы также должны уделить некоторое время Grafana. Но это не одно и то же, и они не полностью конкурируют друг с другом.
Основной функцией Kibana является запрос и анализ данных. Используя различные методы, пользователи могут искать в данных, проиндексированных в Elasticsearch, определенные события или строки в данных для анализа и диагностики первопричин. На основе этих запросов пользователи могут использовать функции визуализации Kibana, которые позволяют визуализировать данные различными способами, используя графики, таблицы, географические карты и другие виды визуализации.
Grafana фактически началась как форк Kibana, целью Grafana была поддержка метрик и мониторинга, которые в то время Kibana не предоставляла.
Grafana - это бесплатный инструмент визуализации данных с открытым исходным кодом. Обычно мы видим Prometheus и Grafana вместе в полевых условиях, но мы также можем увидеть Grafana вместе с Elasticsearch и Graphite.
Ключевое различие между этими двумя инструментами - это логирование и мониторинг. В начале раздела мы рассмотрели мониторинг с помощью Nagios, затем Prometheus и перешли к логированию, где мы рассмотрели стеки ELK и EFK.
Grafana предназначена для анализа и визуализации таких показателей, как использование системного процессора, памяти, дисков и ввода-вывода. Платформа не позволяет выполнять полнотекстовые запросы данных. Kibana работает поверх Elasticsearch и используется в основном для анализа сообщений журнала.
Как мы уже выяснили, Kibana довольно проста в развертывании, а также в выборе места установки, то же самое можно сказать и о Grafana.
Оба поддерживают установку на Linux, Mac, Windows, Docker или сборку из исходников.
Несомненно, есть и другие, но Grafana - это инструмент, который, по моим наблюдениям, охватывает виртуальные, облачные и облачно-нативные платформы, поэтому я хотел рассказать о нем в этом разделе.
Оператор Prometheus + развертывание Grafana
Мы уже рассказывали о Prometheus в этом разделе, но поскольку мы так часто видим эти пары, я хотел создать среду, которая позволила бы нам хотя бы увидеть, какие метрики мы могли бы отображать в визуализации. Мы знаем, что мониторинг наших сред очень важен, но просмотр этих метрик в Prometheus или любом другом метрическом инструменте будет громоздким и не будет масштабироваться. Именно здесь на помощь приходит Grafana, которая предоставляет нам интерактивную визуализацию этих метрик, собранных и сохраненных в базе данных Prometheus.
С помощью этой визуализации мы можем создавать пользовательские графики, диаграммы и оповещения для нашей среды. В этом руководстве мы будем использовать наш кластер minikube.
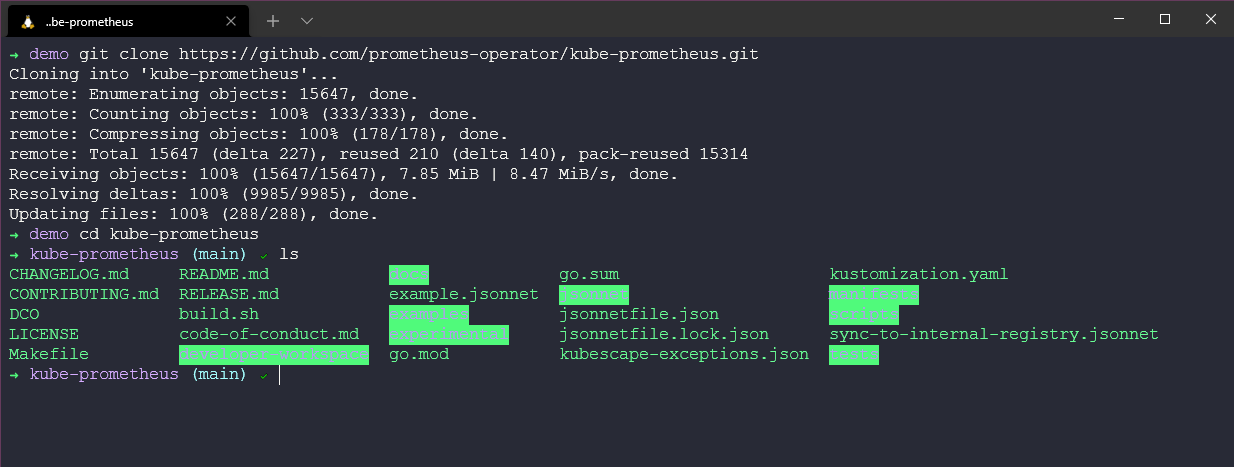
Для начала мы клонируем его в нашу локальную систему. Используя git clone https://github.com/prometheus-operator/kube-prometheus.git и cd kube-prometheus.
Первая задача - создать наше пространство имен в кластере minikube kubectl create -f manifests/setup, если вы не следили за предыдущими разделами, мы можем использовать minikube start для создания нового кластера.

Далее мы собираемся развернуть все необходимое для нашего демо с помощью команды kubectl create -f manifests/, как вы можете видеть, это развернет множество различных ресурсов в нашем кластере.
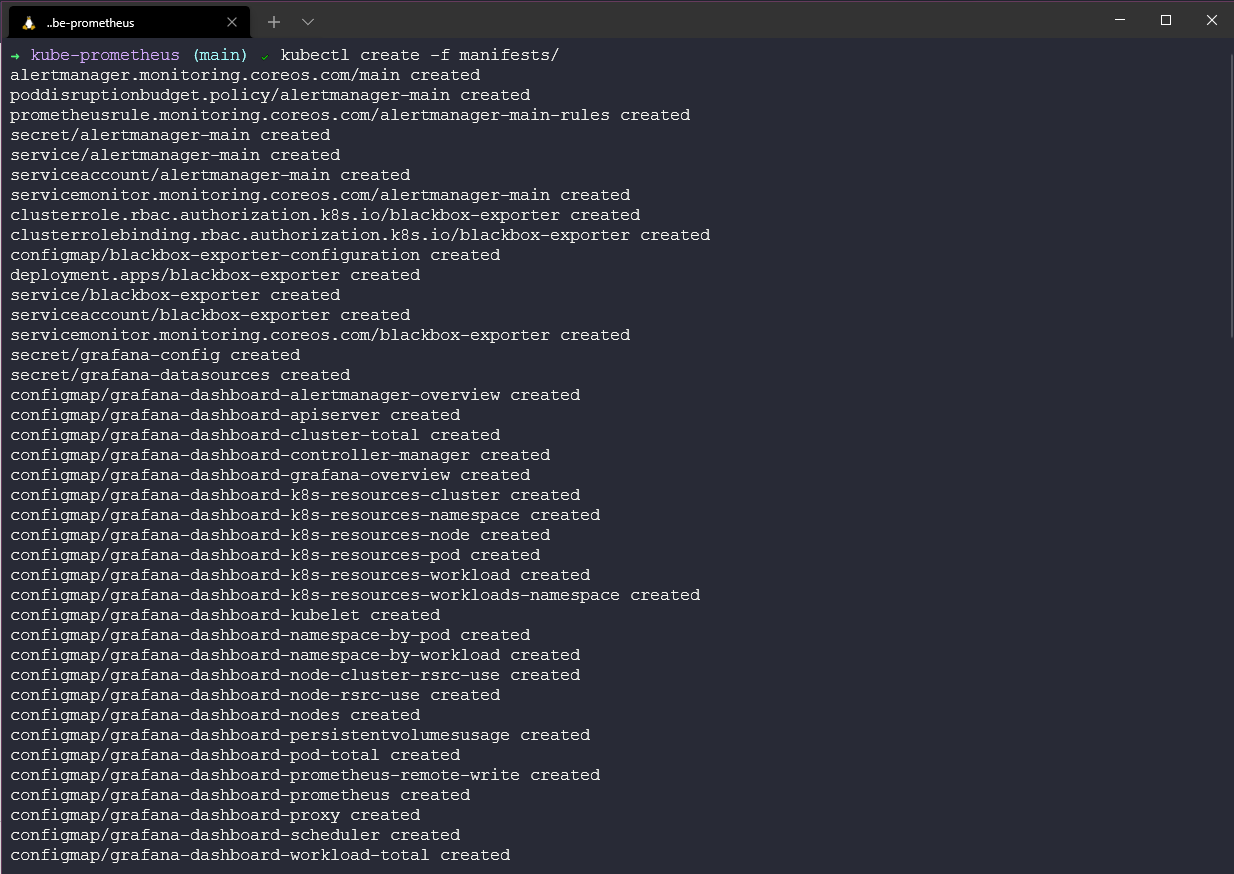
Затем нам нужно подождать, пока наши стручки поднимутся, и, находясь в запущенном состоянии, мы можем использовать команду kubectl get pods -n monitoring -w, чтобы следить за стручками.
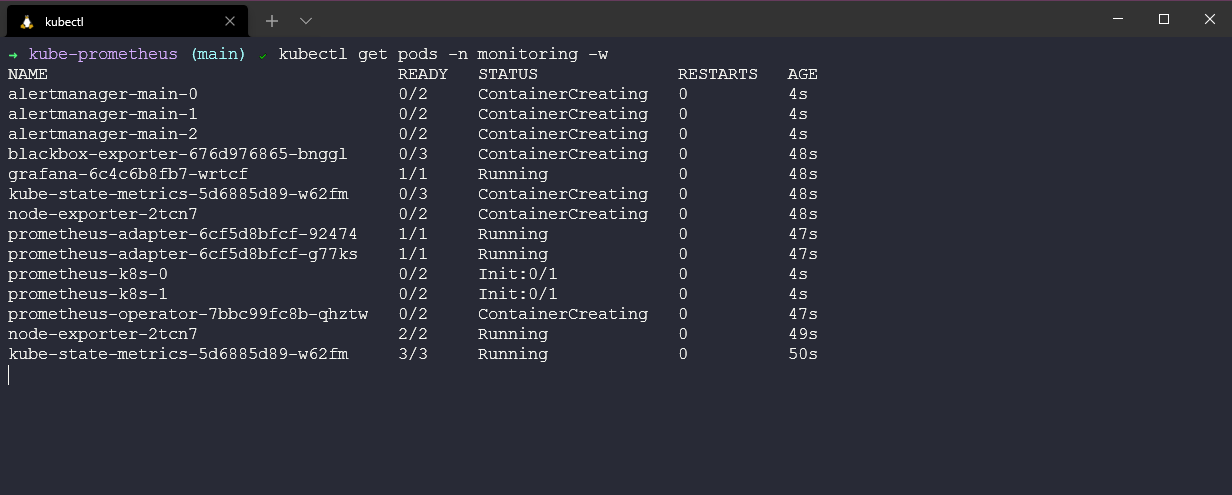
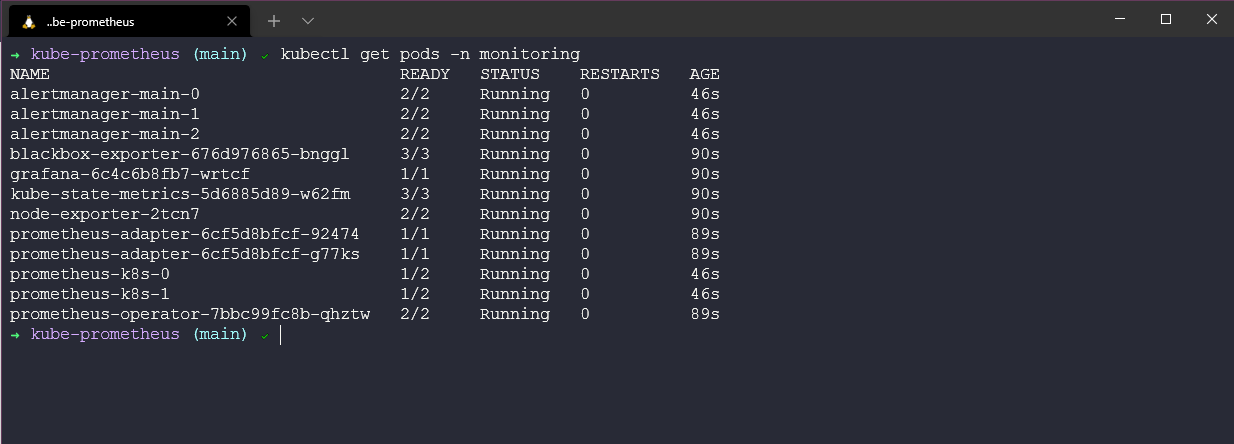
Когда все запущено, мы можем проверить, что все pods находятся в рабочем и здоровом состоянии, используя команду kubectl get pods -n monitoring.
При развертывании мы развернули ряд сервисов, которые мы будем использовать позже в демо, вы можете проверить их с помощью команды kubectl get svc -n monitoring.
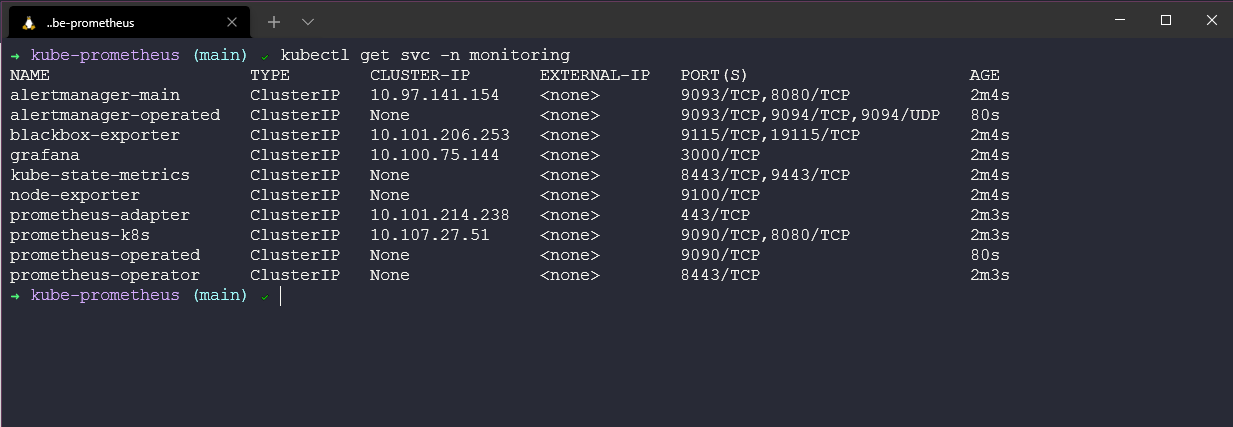
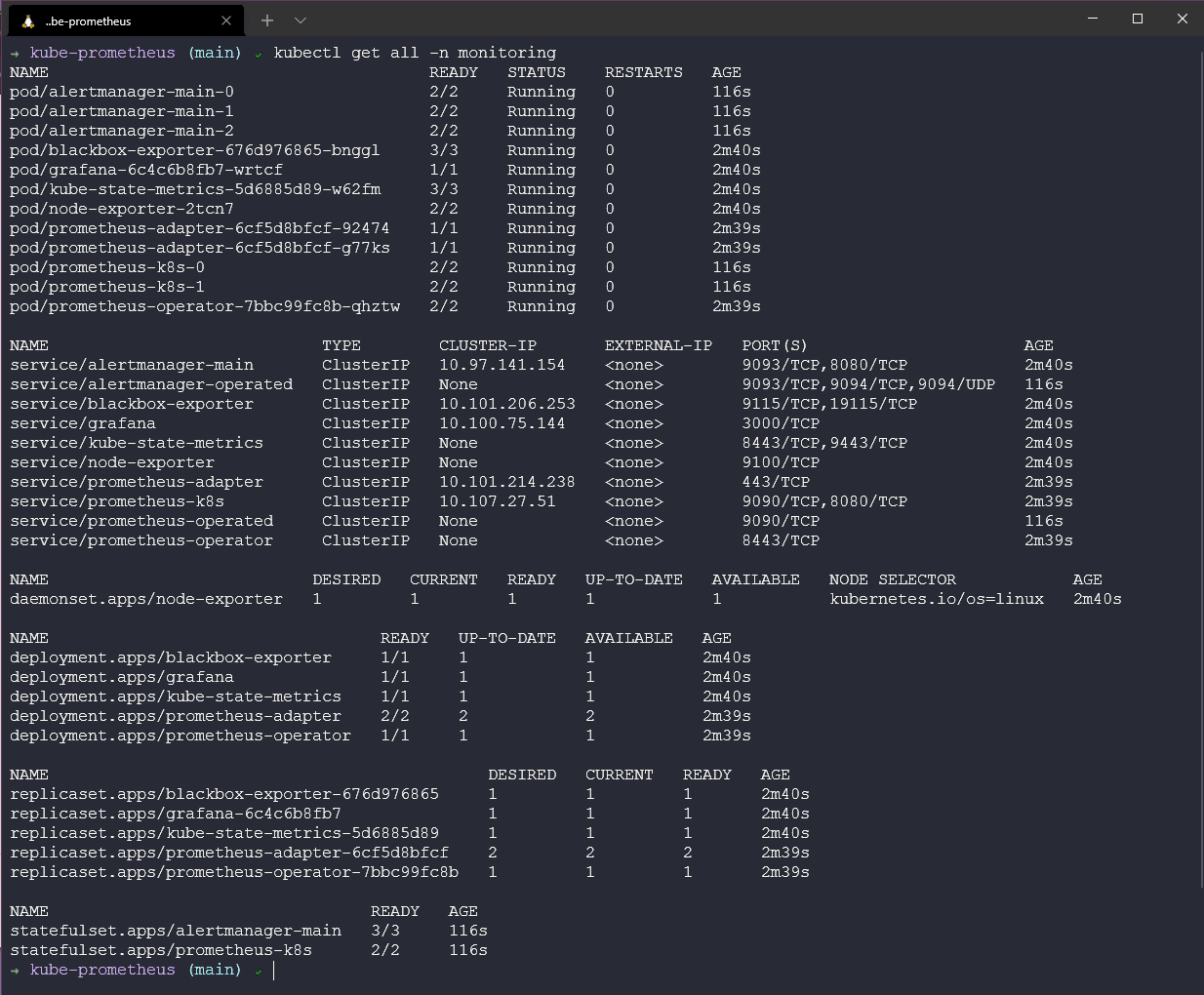
И, наконец, давайте проверим все ресурсы, развернутые в нашем новом пространстве имен мониторинга, используя команду kubectl get all -n monitoring.
Открыв новый терминал, мы готовы получить доступ к нашему инструменту Grafana и начать собирать и визуализировать некоторые из наших метрик, команда для использования - kubectl --namespace monitoring port-forward svc/grafana 3000.
Откройте браузер и перейдите по адресу http://localhost:3000, вам будет предложено ввести имя пользователя и пароль.
Имя пользователя: admin
Пароль: admin
Однако при первом входе в систему вам будет предложено ввести новый пароль. На начальном экране или домашней странице вы увидите несколько областей для изучения, а также некоторые полезные ресурсы для ознакомления с Grafana и ее возможностями. Обратите внимание на виджеты “Добавить свой первый источник данных” и “Создать свою первую приборную панель”, мы будем использовать их позже.
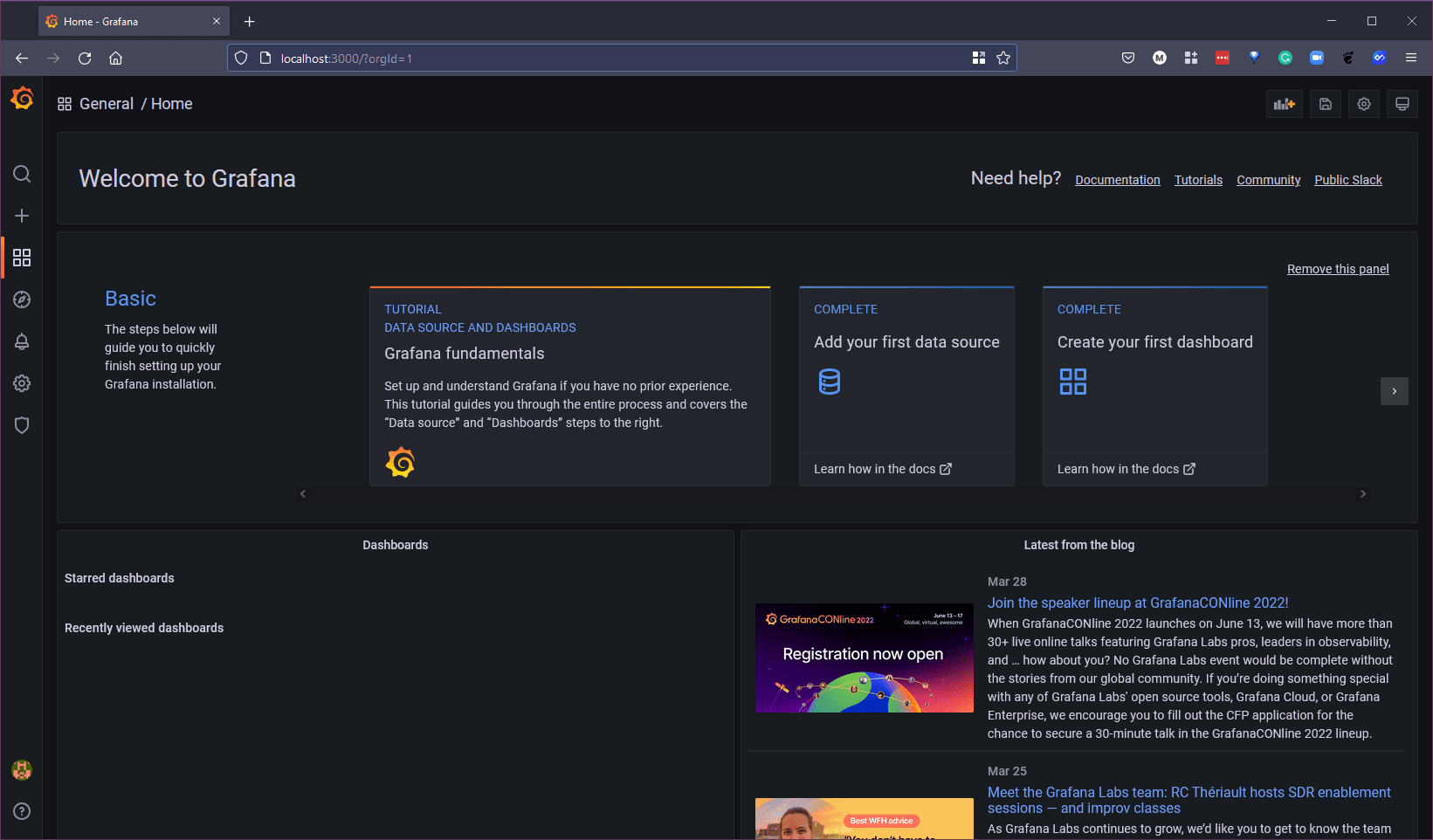
Вы увидите, что источник данных prometheus уже добавлен в источники данных Grafana, однако, поскольку мы используем minikube, нам нужно также перенаправить prometheus, чтобы он был доступен на нашем localhost, открыв новый терминал, мы можем выполнить следующую команду. kubectl --namespace monitoring port-forward svc/prometheus-k8s 9090 если на главной странице Grafana мы теперь заходим в виджет “Add your first data source” и отсюда выбираем Prometheus.
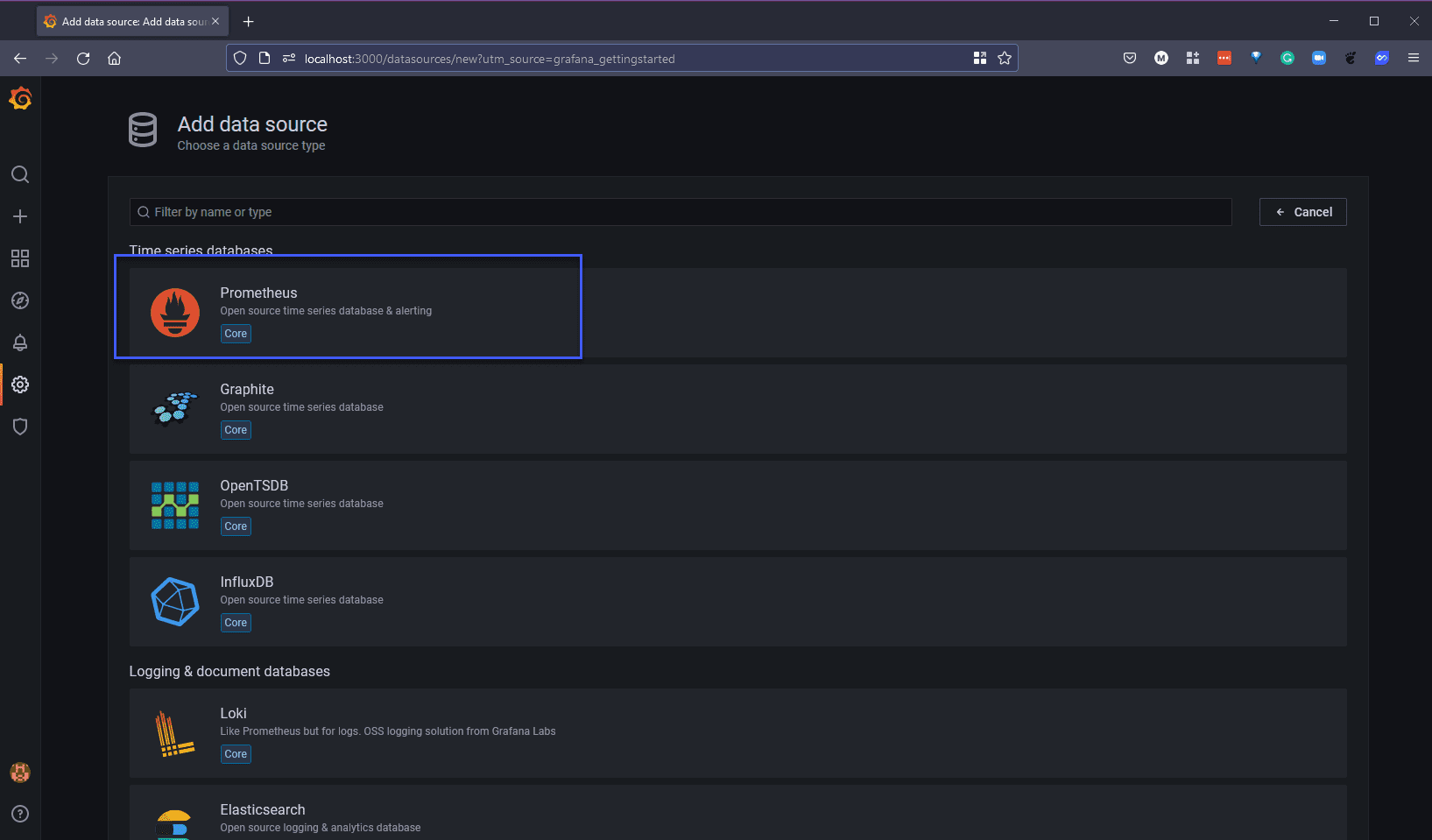
Для нашего нового источника данных мы можем использовать адрес http://localhost:9090, и нам также нужно будет изменить выпадающий список на браузер, как показано ниже.
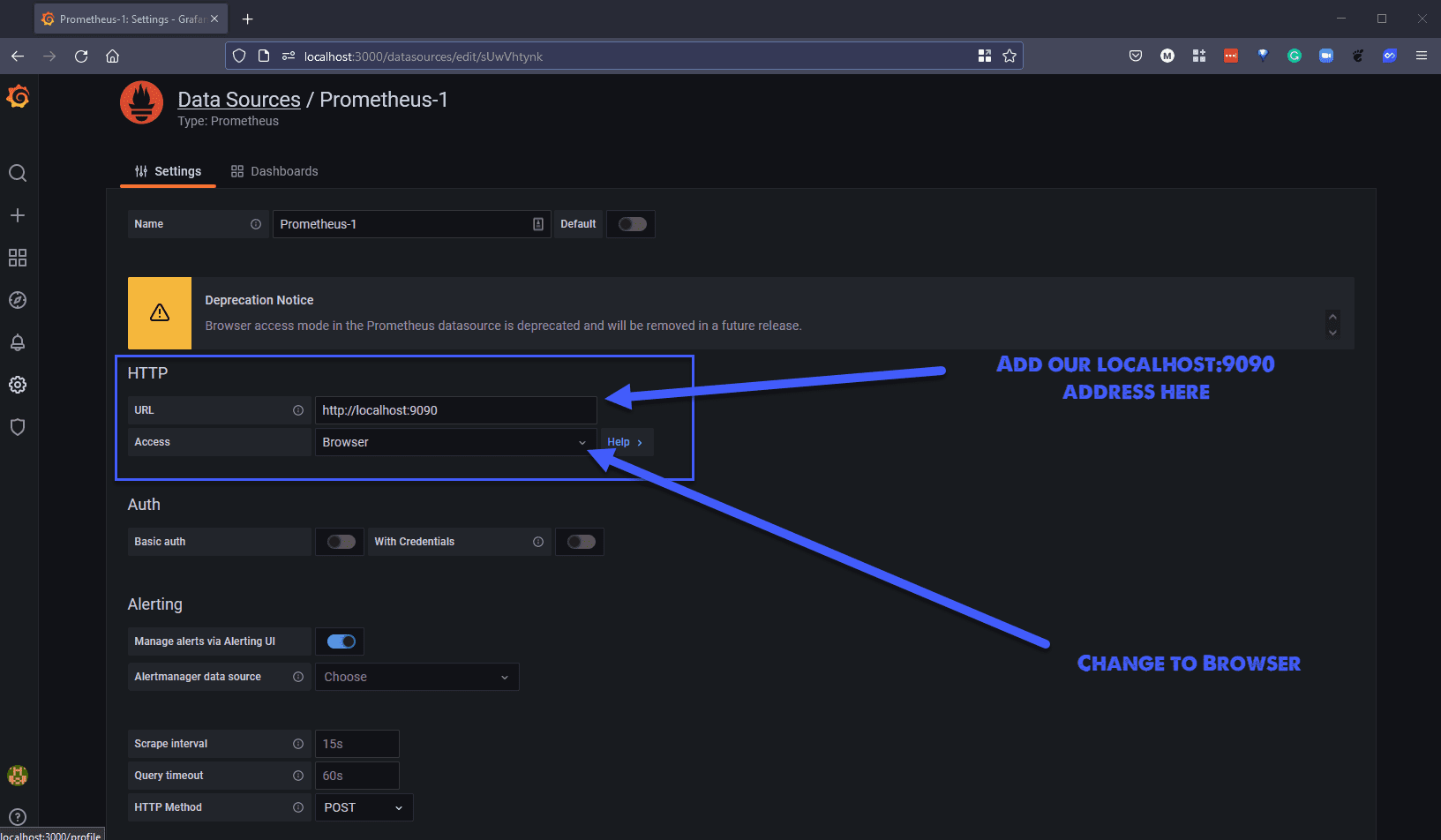
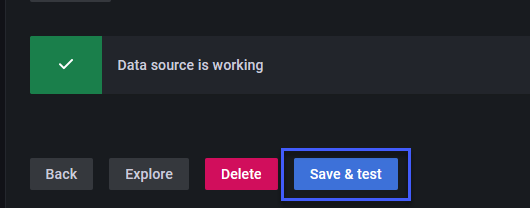
Внизу страницы мы можем нажать кнопку сохранить и протестировать. Это должно дать нам результат, который вы видите ниже, если проброс порта для prometheus работает.
Вернитесь на главную страницу и найдите опцию “Create your first dashboard”, выберите “Add a new panel”.
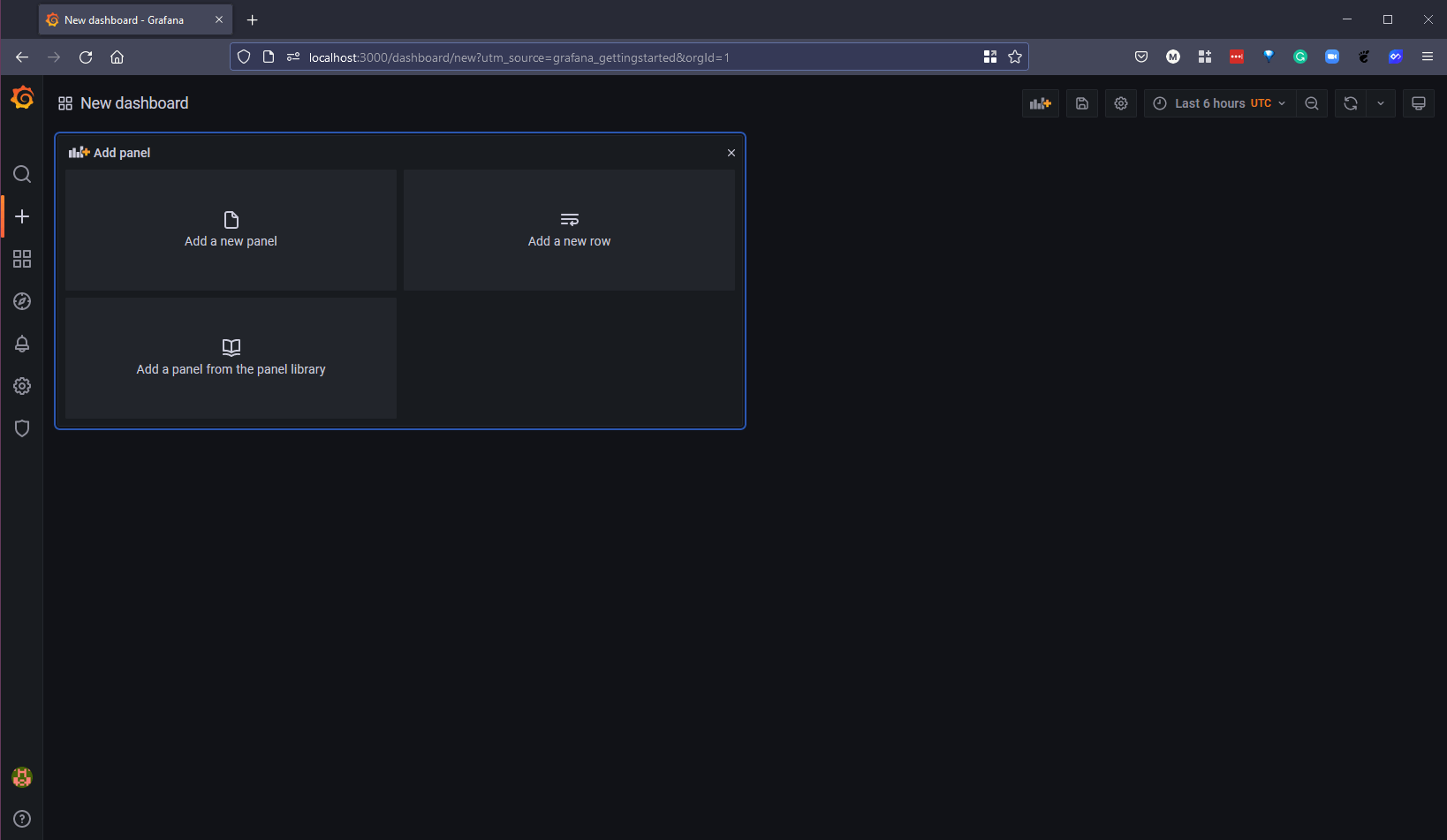
Ниже вы увидите, что мы уже собираем данные из нашего источника данных Grafana, но мы хотели бы собирать метрики из нашего источника данных Prometheus, выберите выпадающий список источников данных и выберите наш недавно созданный “Prometheus-1”
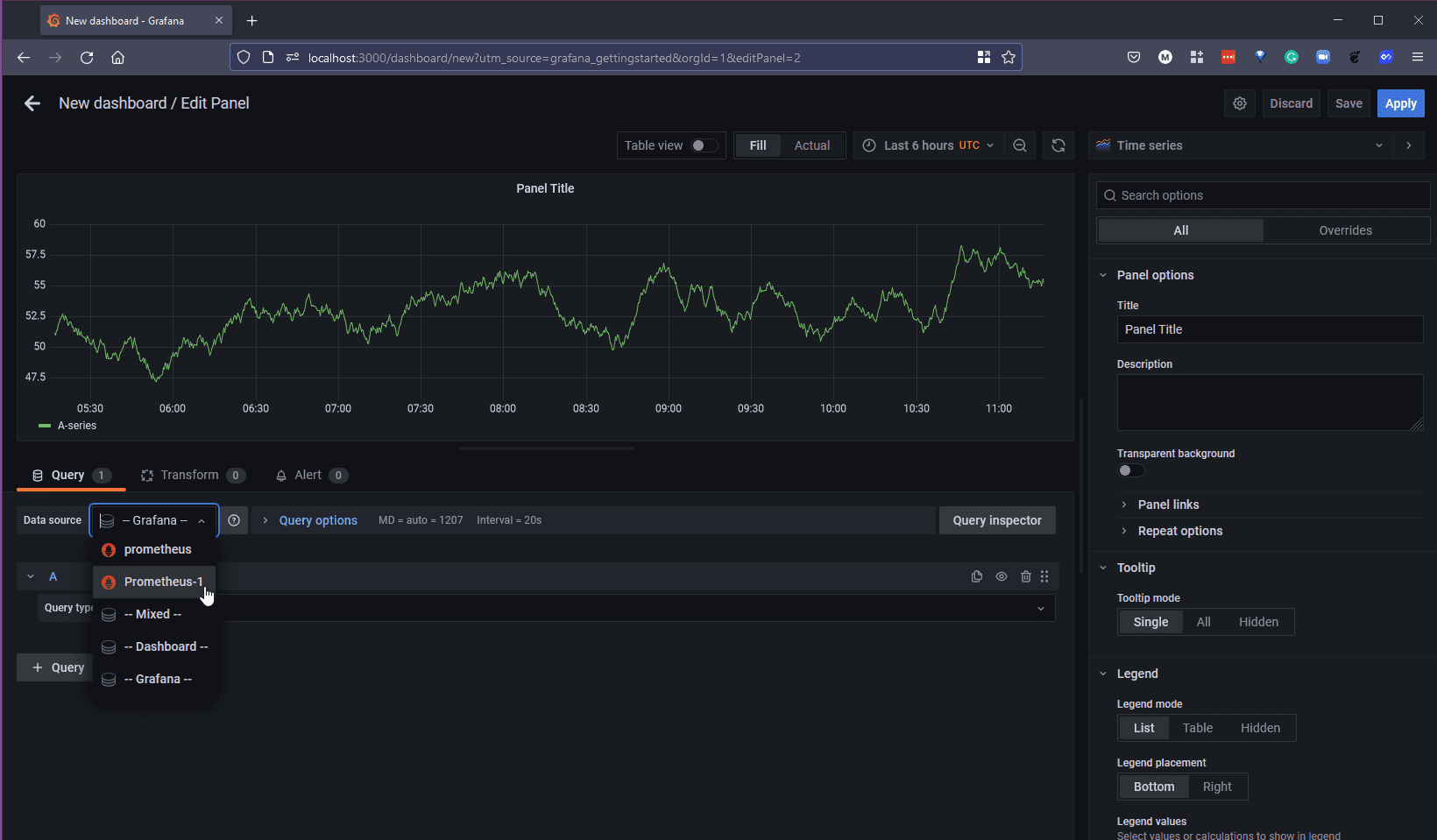
Если затем выбрать браузер Metrics, то появится длинный список метрик, собираемых из Prometheus, связанных с нашим кластером minikube.
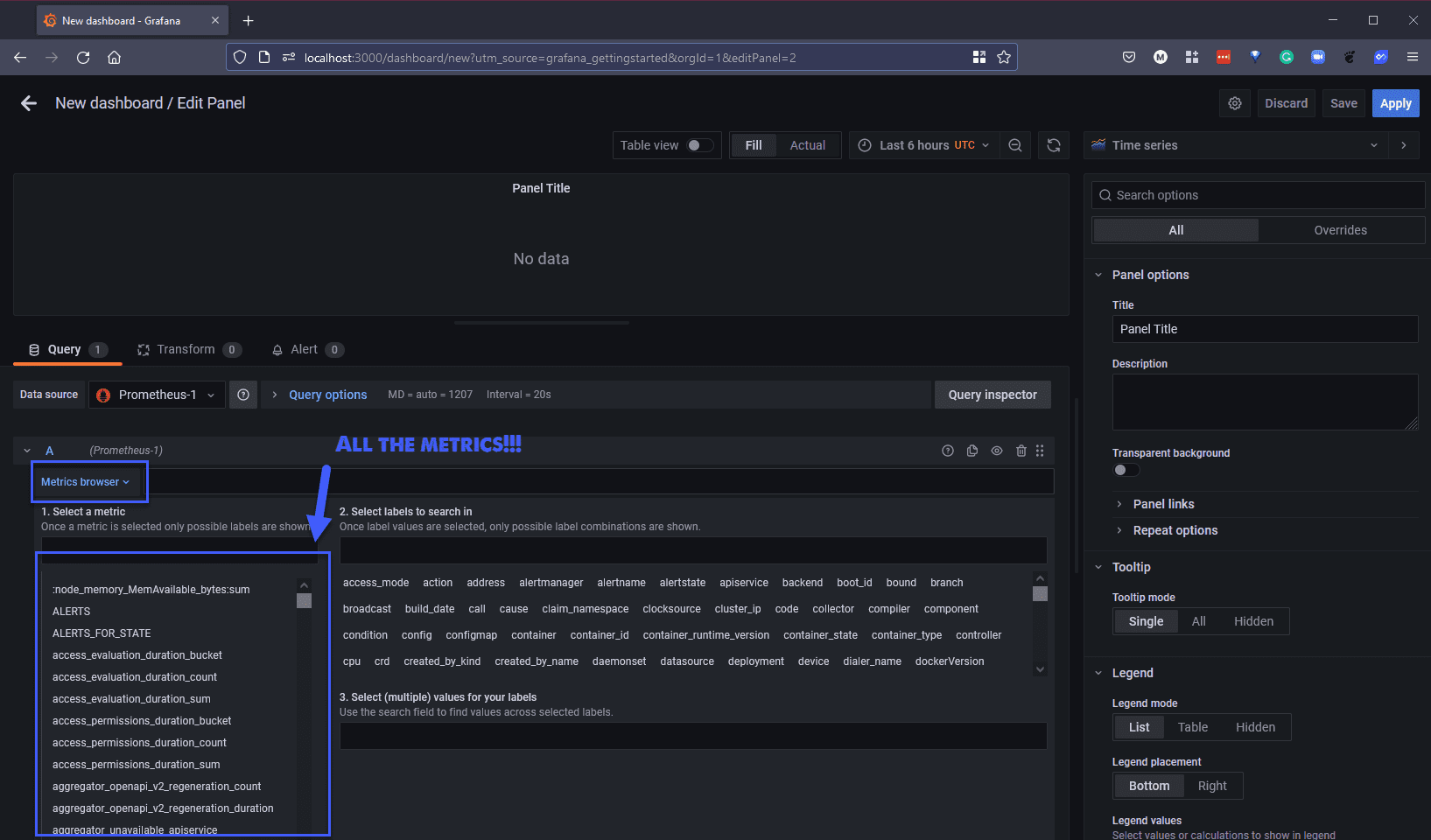
Для целей демонстрации я собираюсь найти метрику, которая дает нам некоторые данные о наших системных ресурсах, cluster:node_cpu:ratio{} дает нам некоторые подробности об узлах в нашем кластере и доказывает, что эта интеграция работает.
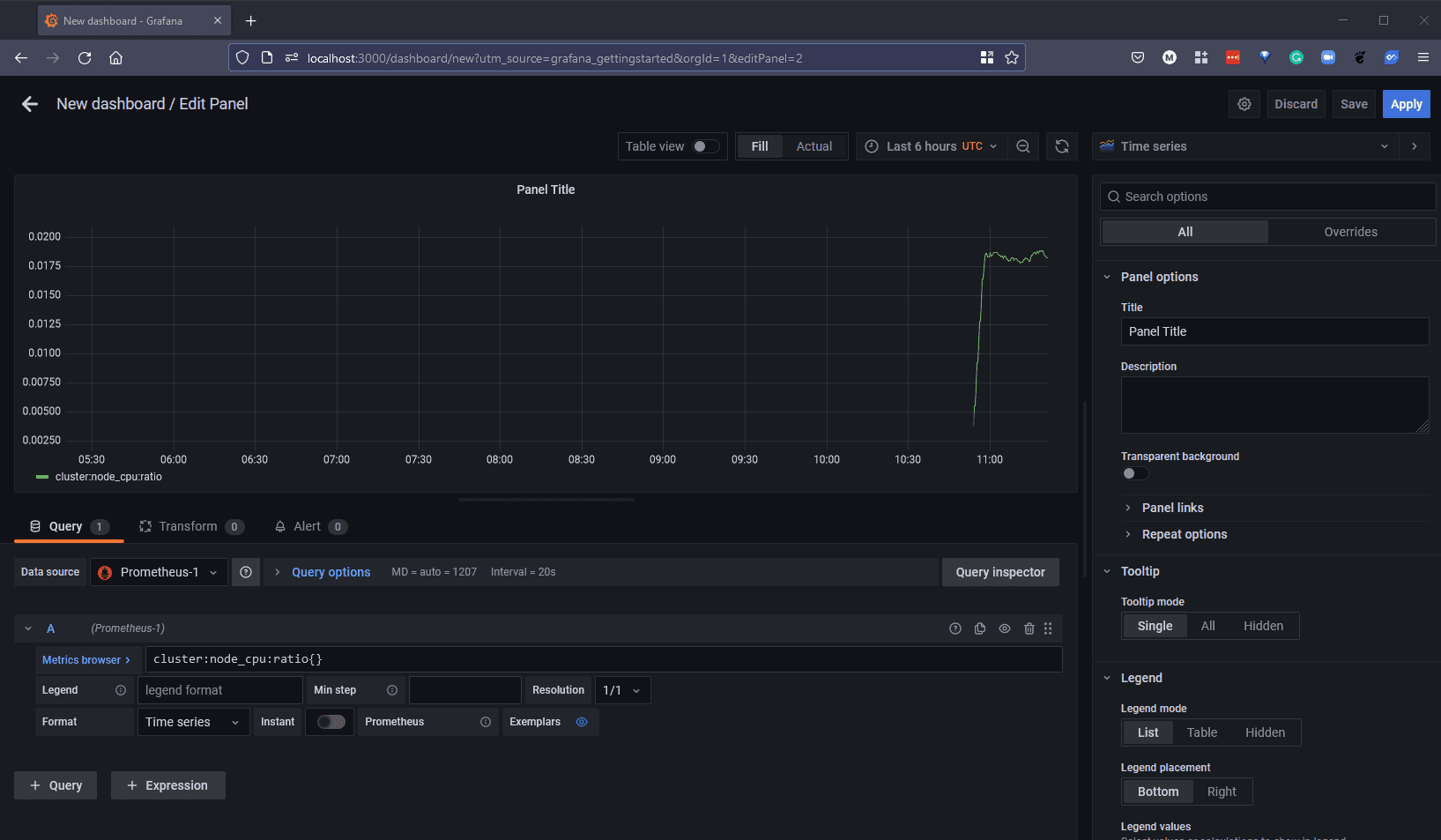
Если вас устраивает такая визуализация, нажмите кнопку “Применить” в правом верхнем углу, и вы добавите этот график на свою приборную панель. Разумеется, вы можете добавлять дополнительные графики и другие диаграммы, чтобы обеспечить нужную вам визуализацию.
Однако мы можем воспользоваться тысячами ранее созданных приборных панелей, которые мы можем использовать, чтобы не изобретать велосипед.
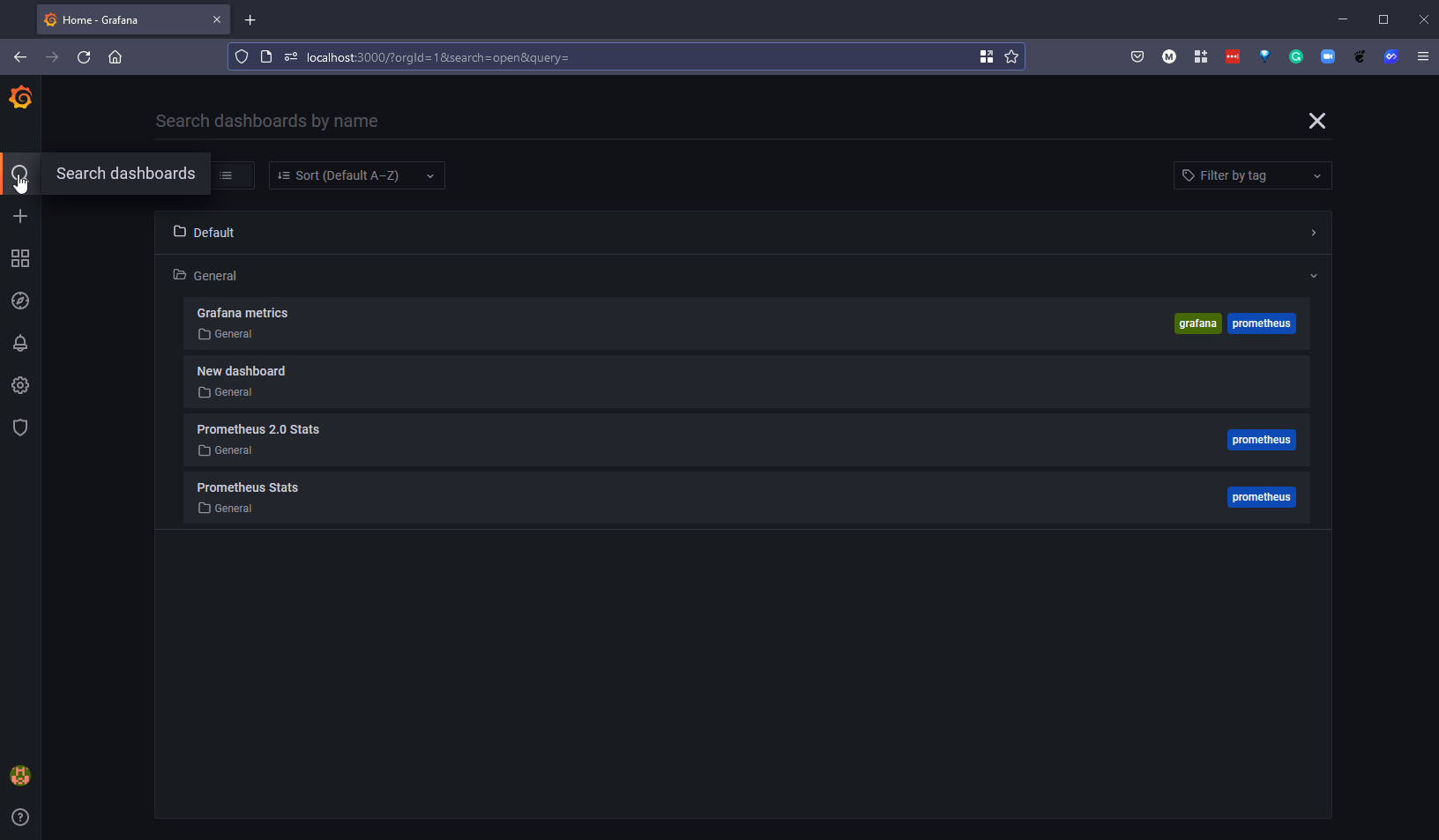
Если мы выполним поиск по Kubernetes, то увидим длинный список готовых приборных панелей, из которых мы можем выбирать.
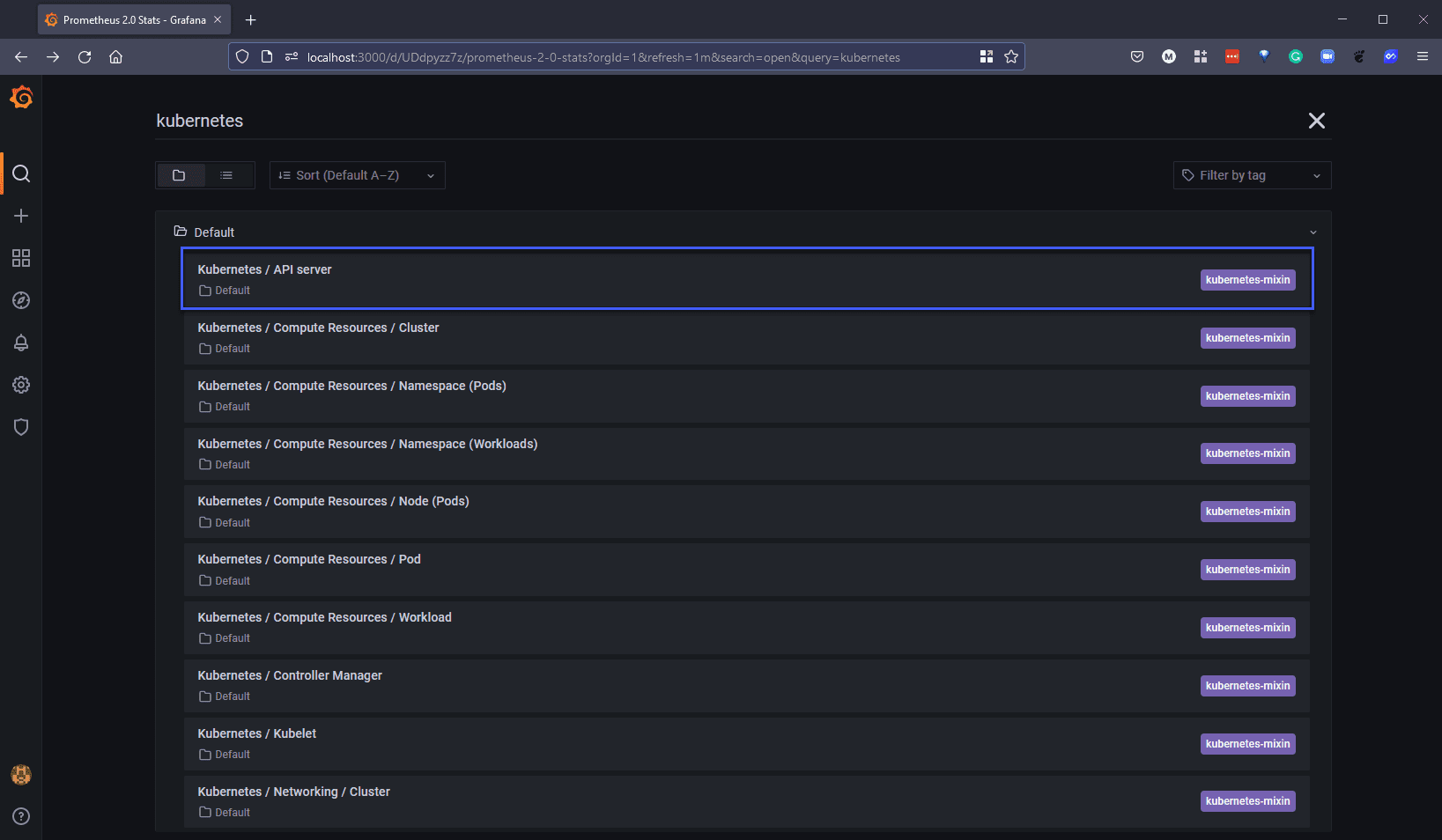
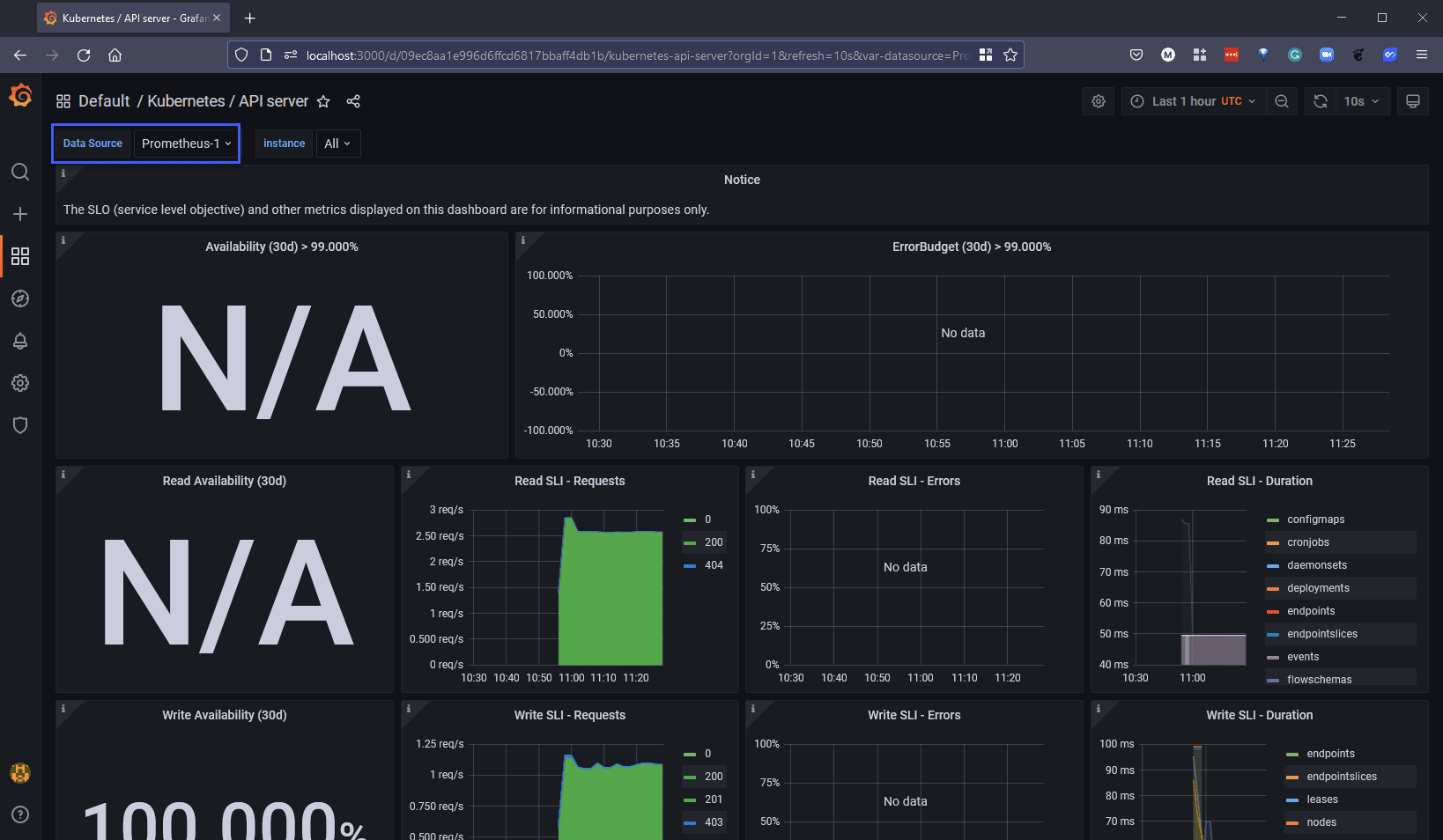
Мы выбрали приборную панель Kubernetes API Server и изменили источник данных, чтобы соответствовать нашему недавно добавленному источнику данных Prometheus-1, и мы видим некоторые метрики, отображаемые как показано ниже.
Оповещение
Вы также можете использовать развернутый нами alertmanager для отправки оповещений в slack или другие интеграции, для этого вам нужно перенести сервис alertmanager, используя следующие данные.
kubectl --namespace monitoring port-forward svc/alertmanager-main 9093
http://localhost:9093
На этом мы завершаем наш раздел о наблюдаемости. Лично я считаю, что этот раздел подчеркнул, насколько широка эта тема, но в равной степени, насколько она важна для наших ролей, и что будь то метрика, логирование или трассировка, вам необходимо иметь хорошее представление о том, что происходит в наших широких средах в будущем, особенно когда они могут так сильно измениться благодаря автоматизации, которую мы уже рассмотрели в других разделах.
Далее мы рассмотрим управление данными и то, как принципы DevOps также необходимо учитывать, когда речь идет об управлении данными.
Ресурсы
- Understanding Logging: Containers & Microservices
- The Importance of Monitoring in DevOps
- Understanding Continuous Monitoring in DevOps?
- DevOps Monitoring Tools
- Top 5 - DevOps Monitoring Tools
- How Prometheus Monitoring works
- Introduction to Prometheus monitoring
- Promql cheat sheet with examples
- Log Management for DevOps | Manage application, server, and cloud logs with Site24x7
- Log Management what DevOps need to know
- What is ELK Stack?
- Fluentd simply explained