CloudFormation
On This Page
About
CloudFormation enables the user to design & provision AWS infrastructure deployments predictably & repeatedly
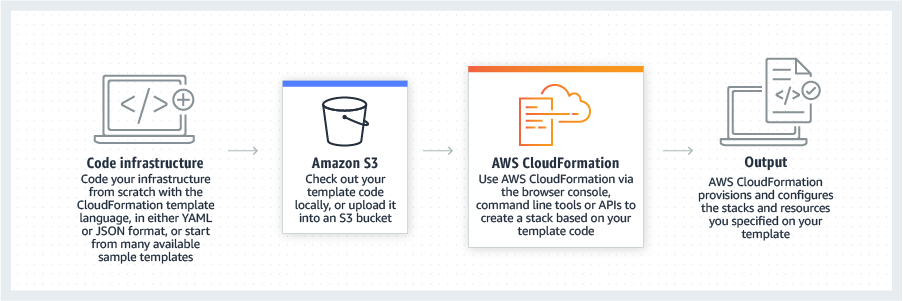
Terminology
| Component | Description |
|---|---|
| Templates | The JSON or YAML text file that contains the instructions for building out the AWS environment |
| Stacks | The entire environment described by the template and created, updated, and deleted as a single unit |
| StackSets | AWS CloudFormation StackSets extends the functionality of stacks by enabling you to create, update, or delete stacks across multiple accounts and regions with a single operation |
| Change Sets | A summary of proposed changes to your stack that will allow you to see how those changes might impact your existing resources before implementing them |
Template
The main sections in a CloudFormation template:
- Parameters - specify variables requiring user input
- Conditions - define entities based on a condition e.g. provision resources based on environment, or specify AMI for and EC2 instance to deploy based on region
- Resources - the AWS resources to create
- Mappings - create custom mappings e.g. RegionMap for Region : AMI
- Transforms - reference code located in S3 e.g. Lambda code or reusable snippets of CloudFormation code
Digest
- A CloudFormation template will consist of a set of resources defined. These resources will be part of a single stack, once built. CloudFormation will treat all the resources as a collection of resources
- CloudFormation supports JSON and YAM for its template languages.
- All ID’s are unique to each region, account, and VPC. It is best practice to not embed such IU’s inside a CloudFormation template. Instead, define parameters, mappings and conditions to create a dynamic template that could be run across VP’s, Regions or even accounts
- Cloudformation stackset vs changeset vs nested stack
- Nested stacks - stacks created as part of other stacks. You create a nested stack within another stack by using the AWS: CloudFormation:Stack resource. For example, assume that you have a load balancer configuration that you use for most of your stacks. Instead of copying and pasting the same configurations into your templates, you can create a dedicated template for the load balancer. Then, you just use the resource to reference that template from within other templates
- Change Sets will produce a summary of changes and their impact on the resources.
- StackSets is used for deploying or managing template resources across accounts and/or regions.
- Sting, Number, List are supported data type in CFT
- Including lambda function as zipfile parameter in CFT is the easiest way to deploy lambda function
- If stack creation fails, AWS CloudFormation rolls back any changes by deleting the resources that it created.
- Fn:FindInMap to perform a dynamic lookup in Cloud formation template
- Transform section of Cloud formation specifies version of SAM model to use.
- Two templates, one for Intra and one for App.
Price
Use Cases
Type: Provision
Same type services: CloudFormation, Service Catalog, OpsWorks, Marketplace
Manage infrastructure with DevOps
Automate, test, and deploy infrastructure templates with continuous integration and delivery (CI/CD) automations.
Scale production stacks
Run anything from a single Amazon Elastic Compute Cloud (EC2) instance to a complex multi-region application.
Share best practices
Define an Amazon Virtual Private Cloud (VPC) subnet or provisioning services like AWS OpsWorks or Amazon Elastic Container Service (ECS) with ease.
Compare
CloudFormation vs Elastic Beanstalk
| CloudFormation | Elastic Beanstalk |
|---|---|
| “Template-driven provisioning” | “Web apps made easy” |
| Deploys infrastructure using code | Deploys applications on EC2 (PaaS) |
| Can be used to deploy almost any AWS service | Deploys web applications based on Java, .NET, PHP, Node.js, Python, Ruby, Go, and Docker |
| Uses JSON or YAML template files | Uses ZIP or WAR files |
| Similar to Terraform | Similar to Google App Engine |
Comparing CloudFormation Init and EC2 User Data
CloudFormation Init and EC2 User Data
With EC2 Instance user data, developers are able to run commands and scripts during the launch of an EC2 instance. User data can be used to install necessary packages, update the ownership of files and directories, or even update or run services. Developers who are familiar with shell scripting may find user data as the easiest way to incorporate launch instructions for EC2 instances.
EC2 Instance user data allows for a procedural-based approach to configuring an instance during launch.
The following snippet represents a UserData property of an EC2 instance defined within a CloudFormation template:

The shell script above begins with an update and installation of the httpd Apache service using the yum package manager. The systemctl start and enable commands start the Apache server and allow it to serve content from the EC2 instance. The cat command adds an HTML snippet to the index.html file located in the /var/www/html/ directory of the instance. Once the user data script is completed, you can view the HTML content by accessing the EC2 instance’s public URL.
It’s important to note that this user data script runs only when the EC2 instance is launched.
CloudFormation Init (cfn-init)
AWS provides CloudFormation helper scripts like cfn-init to help fine-tune your stack templates to better fit your needs. CloudFormation cfn-init allows developers to establish a desired state of their instance using metadata. This means that these configurations can be updated and run on the same instance over time.
The following snippet represents the AWS::CloudFormation::Init metadata type for an EC2 instance defined within a CloudFormation template:

The config section details the packages, files, and services to be configured on the EC2 instance. This eases the burden of managing a bash script since each type of configuration is held in its own dedicated section. The snippet performs the same configuration on the EC2 instance as the previous user data example.
Unlike EC2 user data, the cfn-init script does not run automatically. The next lab step will cover how to utilize helper scripts in a CloudFormation stack deployment.
Key Differences
- Instance user data is procedural-based, while CloudFormation init can be used to achieve the desired state of an instance
- When you update the instance user data in CloudFormation and perform a stack update, the instance is terminated and replaced. However, when you update the CloudFormation init metadata and perform a stack update, the instance will be updated in place
- Instance user data is run only once during the instance launch
- The success or failure of a user data script does not affect a CloudFormation stack creation process. With the CloudFormation signal helper script, a successful stack creation relies on a successful instance configuration (More on this in the next lab step)
Practice
Initializing Amazon EC2 Instances with AWS CloudFormation Init
Questions
Q1
You are creating multiple resources using multiple CloudFormation templates. One of the resources (Resource B) needs the ARN value of another resource (resource A) before it is created.
What steps can you take in this situation? (Choose 2 answers)
- Use a template to first create Resource A with the ARN as an output value.
- Use a template to create Resource B and reference the ARN of Resource A using
Fn::GetAtt. - Hard code the ARN value output from creating Resource A into the second template.
- Just create Resource B.