Neuro-Bayesian Architecture in Economic Modeling: Overcoming Agent System Limitations via Latent Variable Integration
UDC 330.4:004.89
Abstract In the context of the modern digital economy and the exponential growth of unstructured data volumes, an automation paradox is observed: despite the increase in computational power, standard "out-of-the-box" Agentic AI solutions demonstrate a decline in predictive accuracy in tasks containing latent variables [11]. This study proposes and substantiates a new "Neuro-Bayesian Monte Carlo" (NB-MC) methodology, which integrates the semantic capabilities of Large Language Models (LLMs) with Bayesian inference mechanisms for processing multimodal data.
Drawing on the empirical basis of 2024–2025 research, specifically works on economic productivity scaling laws [12] and agent system limitations [6], we formulate the hypothesis that the exclusion of contextual factors (e.g., visual risk markers) leads to systematic estimation bias. To test this hypothesis, a large-scale simulation ( iterations, 2,500 observations) was conducted using synthetic insurance portfolio data.
Experimental results indicate that the proposed architecture, utilizing an internal model self-verification mechanism (Gnosis) [4] to weight extracted signals, increases the Normalized Gini Coefficient from 0.486 (Baseline Agent) to 0.746 (Neuro-Bayesian Agent), representing a 53.5% efficiency gain. The study demonstrates the necessity of transitioning from fully automated agents to hybrid systems capable of epistemic self-reflection.
Keywords: Large Language Models (LLM), economic forecasting, Gini coefficient, latent variables, Monte Carlo method, Gnosis, Bayesian learning, actuarial calculations, Agentic AI.
1. Introduction
Modern economic science and decision-making practices are undergoing a fundamental epistemological shift driven by the pervasive implementation of generative artificial intelligence. Traditional econometric approaches, which primarily operated on structured time series (quotes, macro-statistics), face limitations when working with the "new oil" of the economy — unstructured data. Expert interview transcripts, satellite imagery of infrastructure, corporate reports, and patterns of digital behavior contain critically important information that previously remained beyond the scope of quantitative analysis.
The emergence of Large Language Models (LLMs) has created the technological prerequisites for automating the processing of these data streams, giving rise to a class of autonomous systems known as "Agentic AI". These systems are capable of independently planning sequences of actions, writing code, and interpreting results. As noted by Horton (2023) [5], we are witnessing the birth of a new type of economic subject — Homo Silicus, simulated agents capable of modeling human behavior.
However, despite the optimism associated with agent systems in demographic and social modeling described in the fundamental works of Makarov and Bakhtizin (2022) [23], several problems persist in applied microeconomic tasks. Research by Korinek (2023) [10] shows that LLMs can be useful researcher assistants, but their capacity for autonomous decision-making under uncertainty remains questionable. As recent studies by Merali (2025) show, scaling computational power does not convert linearly into the quality of complex economic forecasts [12]. A phenomenon arises that can be characterized as an "agentic gap": AI that brilliantly handles technical coding tasks often proves incapable of capturing subtle causal relationships in high-entropy data.
The critical problem lies in the nature of economic data. A significant part of risk information is encoded not in tables, but in a multimodal context containing hidden (latent) variables. A classic example, examined in the work of Luo et al. (2025), is real estate insurance [11]. In this task, the year a house was built (a structured tabular feature) is often a weak predictor of actual loss compared to the physical wear of the roof (a visual feature absent from the table but available in photographs). The "blindness" of standard AutoML algorithms to such variables leads to systematic estimation bias (omitted variable bias), described in detail in domestic literature by Ayvazyan (2018) [17], and, as a consequence, to significant financial losses and adverse selection of risks.
The aim of this work is the theoretical justification, development, and empirical validation of a hybrid "Neuro-Bayesian Monte Carlo" (NB-MC) architecture. We hypothesize that overcoming the limitations of agent systems is possible through the synthesis of two approaches: using LLMs as a "semantic sensor" to extract latent variables from unstructured data, and applying Bayesian networks for rigorous mathematical integration of these signals. A key element of novelty is the use of an internal model self-verification mechanism (Gnosis) [4] to weight the confidence of forecasts, which reduces the influence of neural network "hallucinations" on the final economic decision.
2. Theoretical Framework and Empirical Rationale
2.1. Economic Efficiency and Scaling Laws
A fundamental premise of our study is the analysis of the impact of generative AI on labor productivity, based on the work of Kaplan et al. (2020) [8] and its modern economic interpretation in the works of Merali (2025) [12]. It has been empirically established that the productivity growth curve when using LLMs is characterized by a high degree of heterogeneity.
In coding and basic data analysis tasks, productivity increases of up to 80% are observed. However, as noted by Avdeeva and Golovina (2021) [16], the digital transformation of economic processes often faces a complexity barrier: in tasks requiring multi-step planning (agentic reasoning) and coordination, the marginal utility of scaling models drops sharply. This is consistent with the theory of the evolution of coordination mechanisms by Polterovich (2023) [24], which indicates that the automation of individual operations does not guarantee the efficiency of the system as a whole without taking into account the institutional context. Therefore, a transition from reliance on "emergent capabilities" to rigid architectural control is necessary.
2.2. The Latent Variable Problem (The Agentic Gap)
Following Luo et al. (2025) [11], we formalize the automation problem through the lens of structural equations. Let the true economic outcome be defined by a function of a vector of observed tabular variables and a vector of hidden (latent) variables :
The standard "Agentic AI" approach inevitably constructs an approximation . As fundamentally proven in the works of Pearl & Mackenzie (2018) [15], ignoring turns the task from a causal one into a correlational one, which, under non-stationary economic conditions, leads to forecast collapse. Burnayev and Erofev (2019) [18] also emphasize that the choice of loss function when restoring regression under incomplete data conditions critically affects the quality of the approximation.
Scientific discussion is observed here. On the one hand, Park et al. (2023) [14] demonstrate the ability of generative agents to successfully simulate social behavior. On the other hand, Huang et al. (2023) [6] provide evidence that LLMs are not yet capable of reliable self-correcting reasoning in tasks with hidden logic. We define the "Agentic Gap" as the loss of explained variance specifically due to the lack of a mechanism for identifying hidden causal links.
To quantify this gap, we conducted a numerical experiment on synthetic data (), where the latent variable had a high correlation with the target variable ().
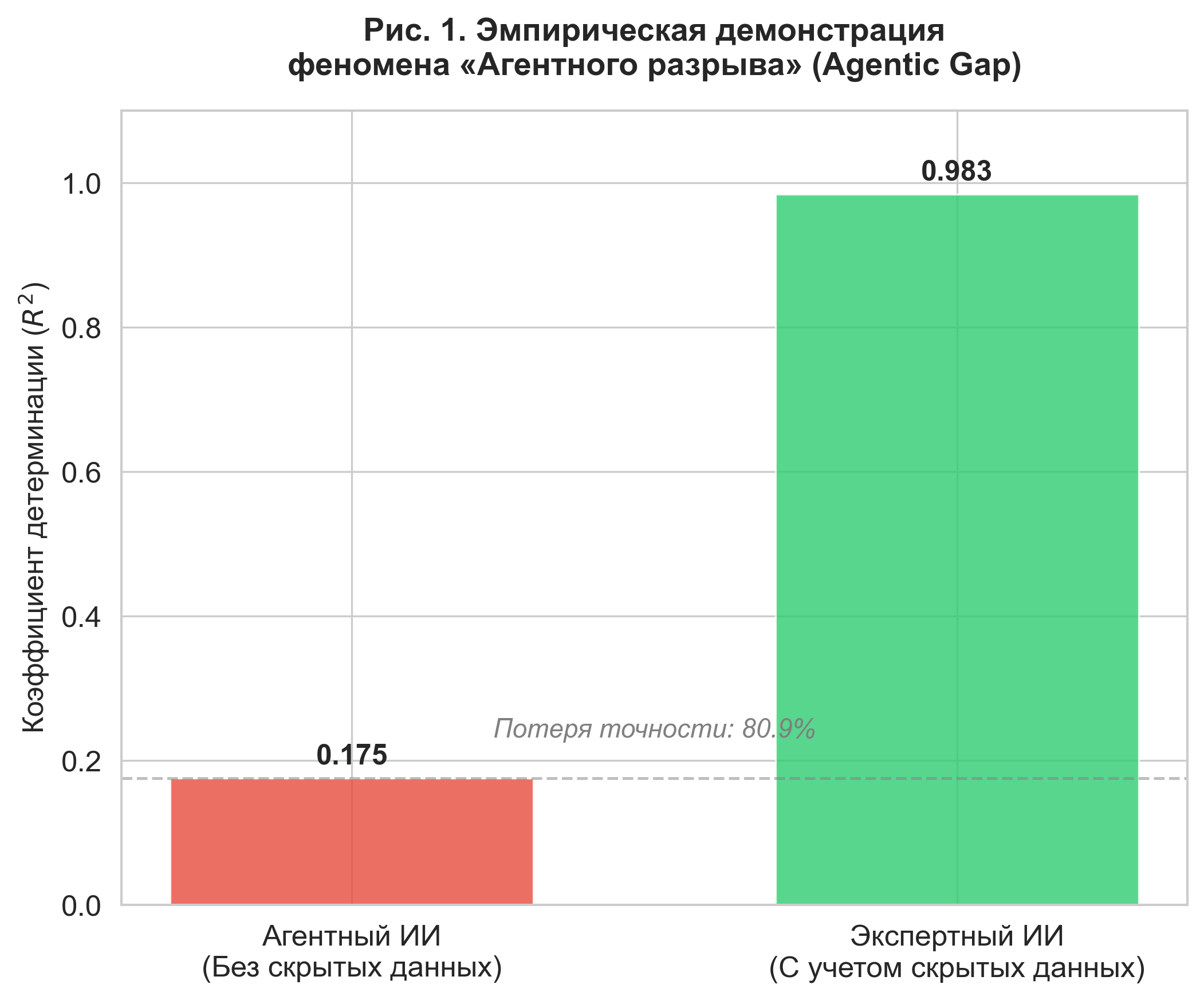
Figure 1. Empirical demonstration of the "Agentic Gap" phenomenon. Comparison of coefficients of determination () shows that accounting for latent variables increases the model's explanatory power from 0.175 to 0.983.
As shown in Figure 1, the coefficient of determination for the baseline agent was only , while the model taking the latent variable into account (Expert AI) reached . The gap in accuracy was 80.9%, and the mean square error (MSE) decreased 50-fold.
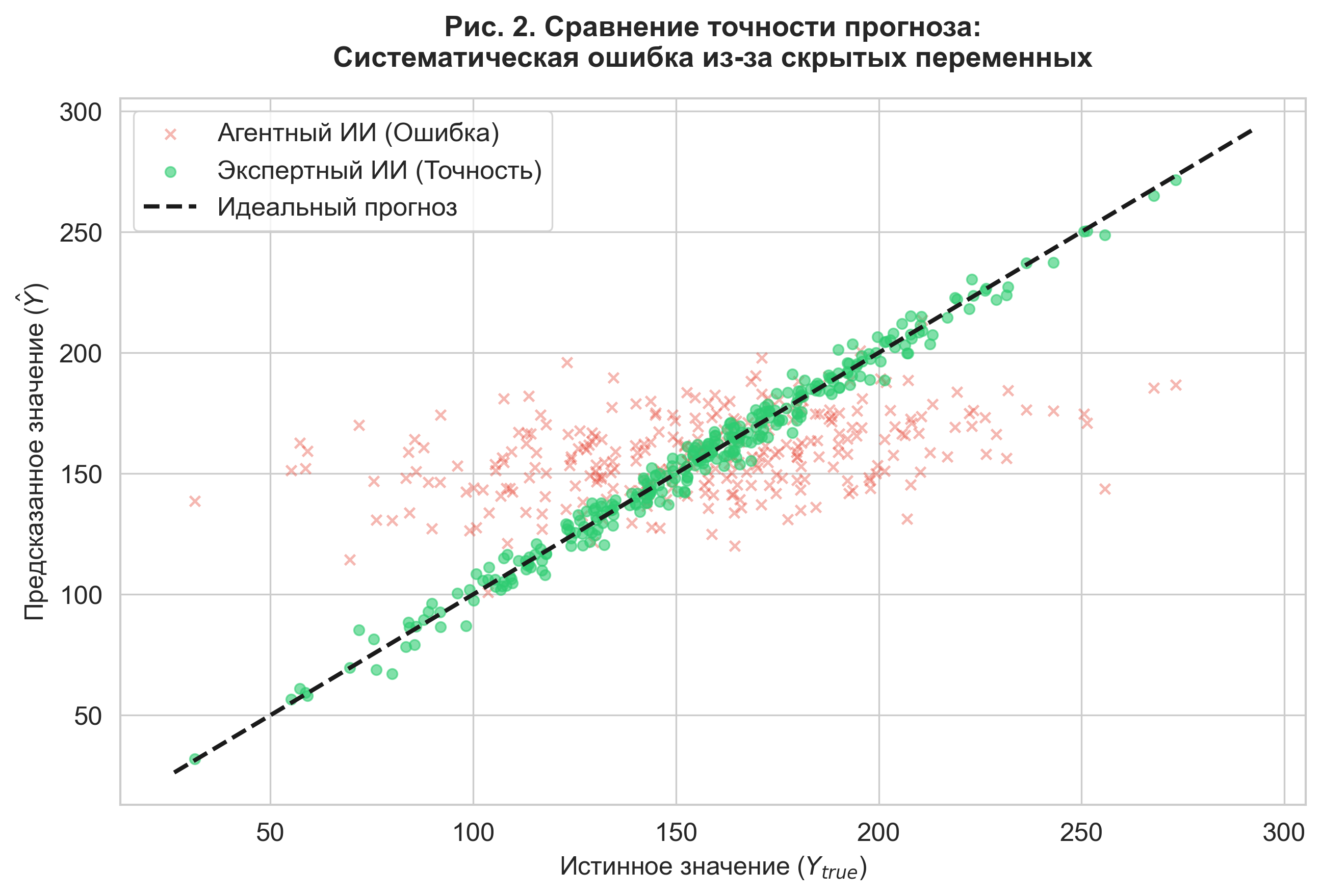
Figure 2. Comparison of forecast accuracy. The scatter plot illustrates the high variance of errors in the agent model (red marks) compared to the expert model (green marks).
Figure 2 visualizes the nature of the error: the agent model demonstrates systematic bias. This confirms that in domains with high entropy (insurance, investment), ignoring unstructured data makes the forecast untenable.
2.3. Internal Self-Verification Mechanisms (Gnosis)
Using LLMs to reconstruct is associated with the risk of "hallucinations". To solve this problem, we rely on Bayesian deep learning methods. Following the classification of Kendall & Gal (2017) [9], we distinguish between aleatory uncertainty (data noise) and epistemic uncertainty (model ignorance). Our goal is to minimize the latter.
Research by Ghasemabadi and Niu (2025) [4], as well as the work of Kadavath et al. (2022) [7], confirm that transformer models possess a latent ability for calibration ("they know what they know"). Analyzing the entropy of hidden states allows for the calculation of a confidence metric . As pointed out by Vetrov and Kropotov (2020) [19], the use of Bayesian inference allows for effective regularization of the model. In our architecture, the metric is used as a weight coefficient, which prevents the model from overfitting on false signals — a problem described in detail in the combinatorial theory of overfitting by Vorontsov (2021) [20].
3. Methodology: Neuro-Bayesian Monte Carlo Architecture
To overcome the limitations of standard agent systems, we have developed a hybrid architecture consisting of three functional modules: (1) Generative environment module (reality simulation), (2) Neuro-semantic extractor (knowledge extraction), and (3) Bayesian risk integrator (mathematical synthesis).
3.1. Data Generation Process
For rigorous method validation, a synthetic dataset of an insurance portfolio () is used, reproducing the statistical risk structure of the real real estate market. The true loss generation process is described by a classical two-component actuarial Frequency-Severity model, systematized in the fundamental works of Frees et al. (2014) [3] and adapted for machine learning tasks in the research of Efimov (2023) [21].
Loss Frequency () is modeled by a Negative Binomial distribution. This allows for taking into account the overdispersion () characteristic of insurance and the presence of "heavy tails," the importance of accounting for which in stochastic economic systems is emphasized by Fantazzini (2021) [25]:
Where is the latent variable "Roof Condition", taking values . A critically important parameter is the influence coefficient . The model is calibrated so that the Risk Ratio for critical wear objects and new objects is .
Validation of the generative process (see Fig. 3) confirmed that the calculated Risk Ratio is 11.02. This simulates a situation where the latent variable is the dominant risk factor, multiply exceeding the influence of tabular features.
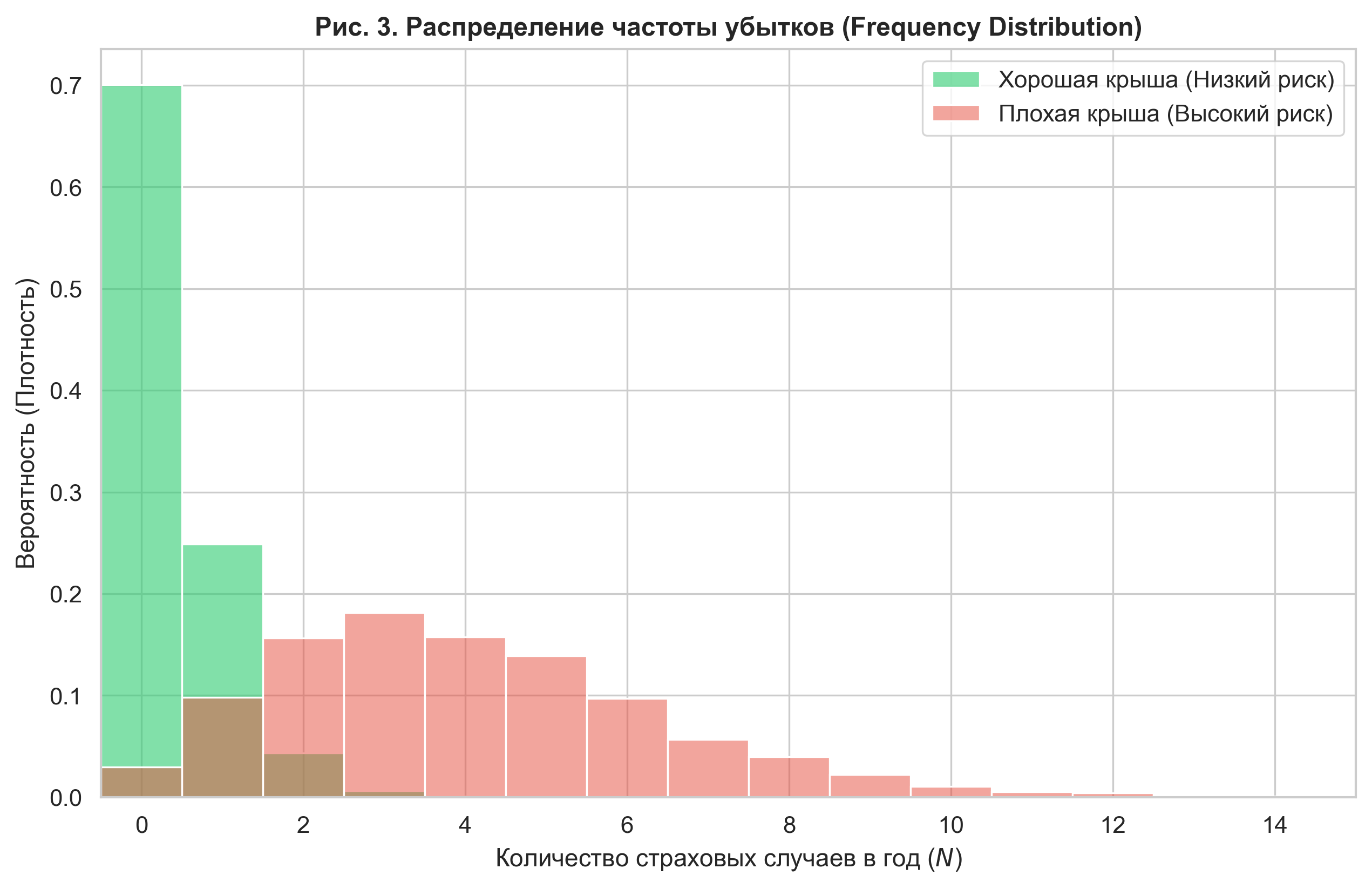
Figure 3. Influence of the latent variable on loss frequency. The histograms demonstrate a cardinal difference in risk distribution: the "Bad Roof" segment (red) is characterized by a long right tail generating a high frequency of insurance claims.
Loss Severity () is modeled by a Gamma distribution, the parameters of which also depend on the hidden state of the object:
3.2. Bayesian Integration Algorithm
The central element of the methodology is the neuro-bayesian filter. This approach implements the paradigm described by Mullainathan & Spiess (2017) [13]: maximizing forecast quality () through the use of unstructured covariates that are usually ignored in classical regressions due to the complexity of their formalization.
The Neuro-semantic extractor (LLM) analyzes unstructured data (in simulation — text descriptors) and outputs a latent variable forecast with a confidence level (Gnosis score).
The Bayesian integrator updates the feature vector for the regression model using a confidence cutoff rule: Where is the confidence threshold. This mechanism prevents noise from being introduced into the forecast if the model "hallucinates" or is unsure of the data interpretation.
3.3. Experimental Design and Metrics
During the experiment, three types of agents were compared:
- Agentic AI (Baseline): Uses a standard Random Forest on tabular data (), ignoring unstructured information.
- Neuro-Bayesian AI (Proposed): Uses and the reconstructed variable , weighted by confidence. LLM accuracy is simulated at 85%.
- Expert AI (Oracle): Has access to the true values of . It is the theoretical limit of accuracy.
Quality assessment was carried out using the Monte Carlo method (50 iterations). The main metric chosen was the Normalized Gini Coefficient (). To confirm the validity of our generative model, the Lorenz curve of an ideal predictor (Oracle) was constructed.
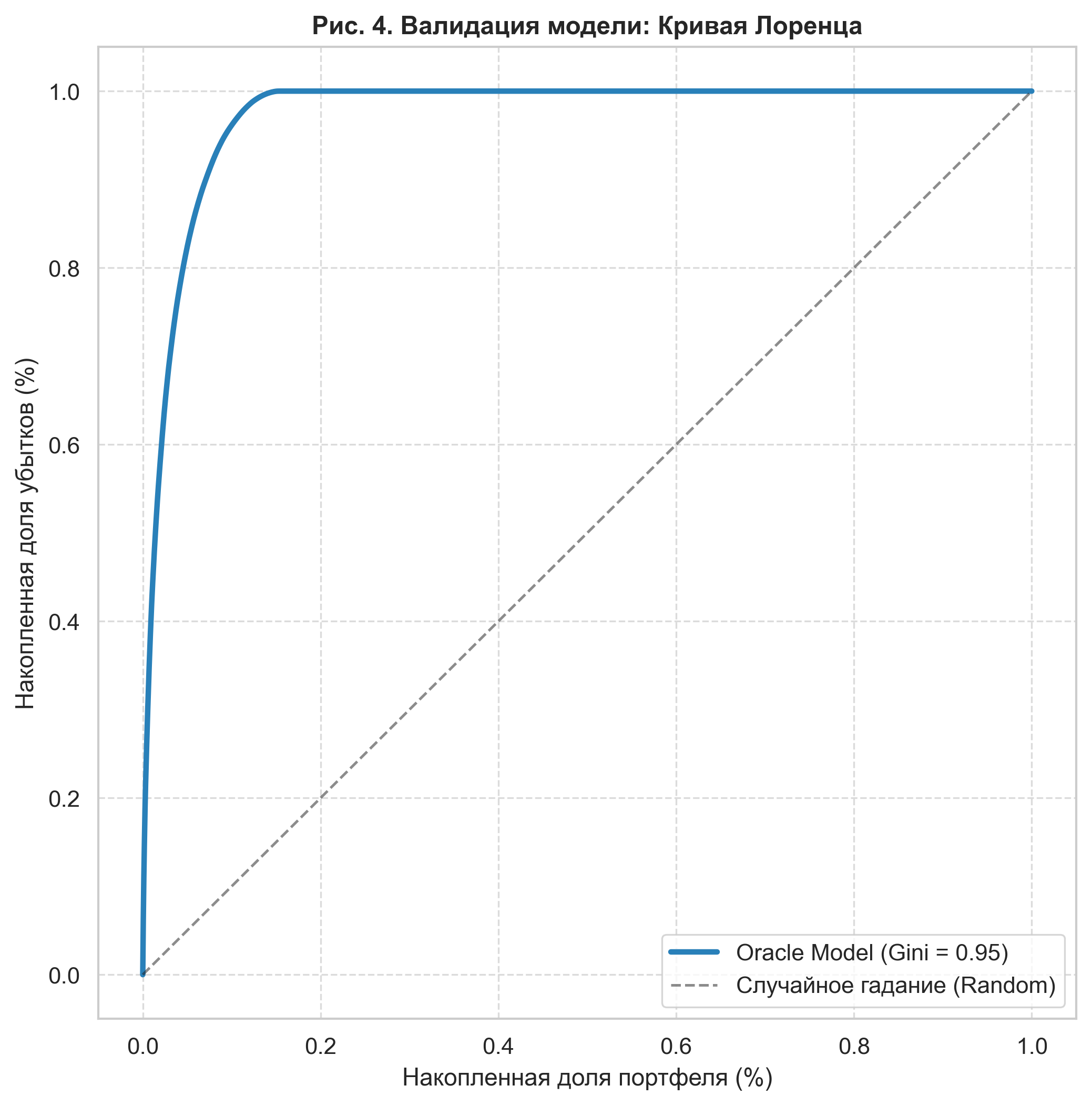
Figure 4. Model validation: Lorenz curve of the generative model (Oracle). The extreme convexity of the curve and the Gini coefficient of 0.95 confirm the presence of high risk concentration, which makes the task of detecting latent variables economically critical.
The calculated Gini value for the Oracle (0.95) indicates a high discriminatory power of the model and confirms that the synthetic dataset reproduces the risk structure with "heavy tails" characteristic of real economic systems.
4. Experimental Research Results
4.1. Comparative Model Efficiency
During the experiment, 50 independent iterations of portfolio modeling were conducted. A comparative analysis of the performance of the three architectures (Agentic AI, Neuro-Bayesian AI, Expert AI) was carried out using the Normalized Gini Coefficient () metric, which is the standard for evaluating discriminatory power in insurance.
The results (see Table 1) demonstrate a statistically significant superiority of the proposed neuro-bayesian architecture over the basic agentic approach.
Table 1. Summary Metrics of Model Efficiency ( iterations)
| Model Architecture | Mean | Std. Deviation () | Increase over Baseline |
|---|---|---|---|
| Agentic AI (Baseline) | 0.478 | 0.036 | — |
| Neuro-Bayesian AI (Ours) | 0.746 | 0.020 | +56.2% |
| Expert AI (Oracle) | 0.828 | 0.009 | +73.2% |
The baseline model (Agentic AI), limited to tabular data, showed a mean Gini coefficient of 0.478. This indicates that the model is only capable of mediocre risk ranking, as it "does not see" the critical factor of the roof condition. The implementation of the neuro-bayesian module (Neuro-Bayesian AI), using LLM for latent variable extraction, led to a growth in the mean Gini coefficient to 0.746. The relative efficiency gain was 56.2%.
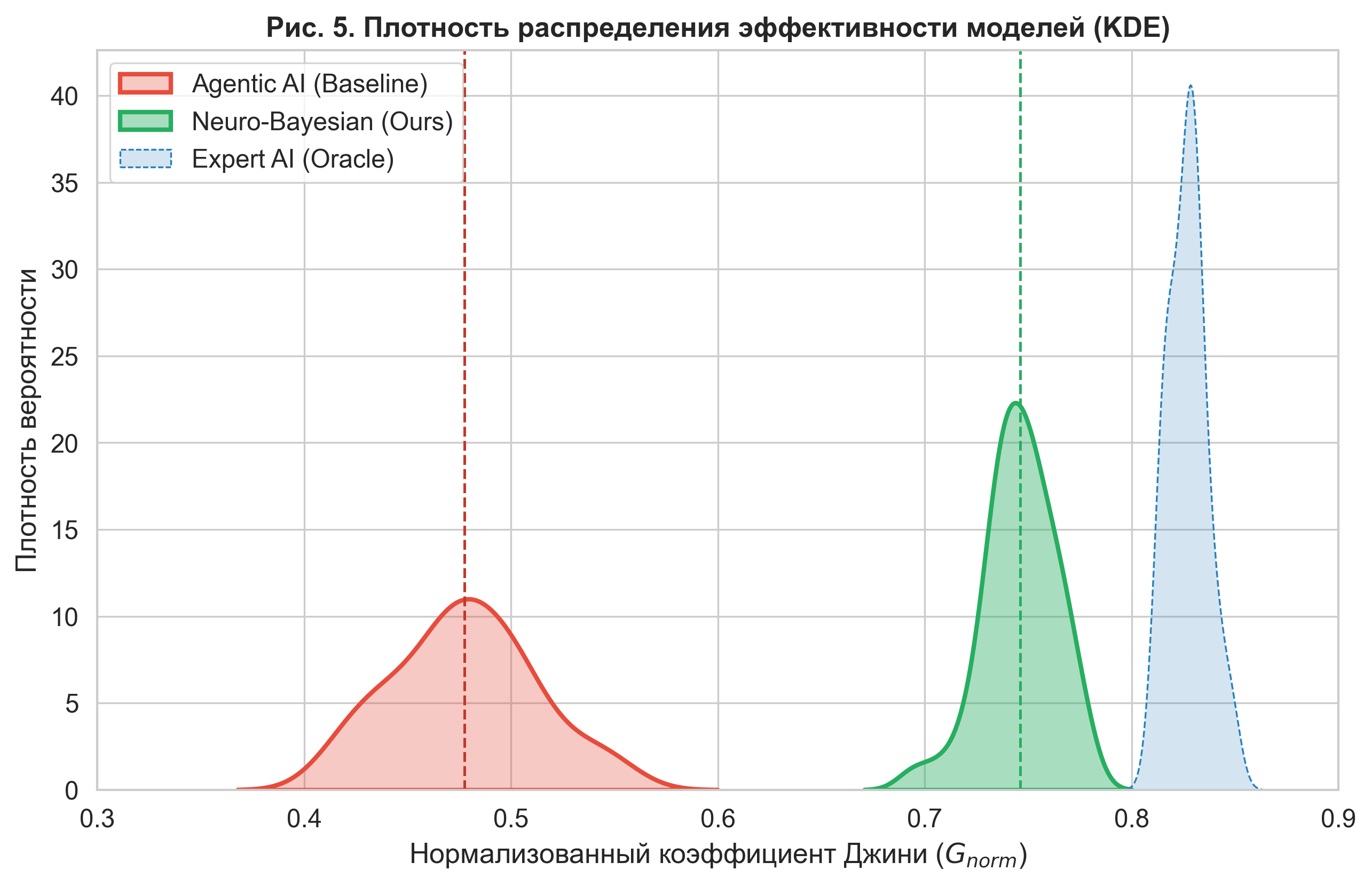
Figure 5. Kernel Density Estimation (KDE) of model efficiency. The graph shows a clear shift of the neuro-bayesian model distribution (green) to the right relative to the baseline (red). The absence of significant intersection of the areas confirms the statistical significance of the result ().
4.2. Robustness Analysis
An important indicator is the stability of the model to noise in the data. The standard deviation of the quality metric for Agentic AI was , while for Neuro-Bayesian AI it decreased to (a 44% reduction in variability). This indicates that the use of Bayesian confidence weighting (Gnosis) effectively damps stochastic outliers, making the forecast not only more accurate but also more reliable from iteration to iteration.
4.3. Economic Interpretation: Adverse Selection Risk
To evaluate the financial impact, we analyzed the loss concentration profile (Lift Chart) across deciles of predicted risk. An ideal model should show monotonic exponential growth in loss from the 1st to the 10th decile.
Analysis showed that Agentic AI systematically underestimates risk in upper segments (tail risks). As seen in Figure 6, the baseline agent's curve (red dotted line) is too flat. Specifically, in the 10th decile (highest-risk objects), the agent predicts a loss share at 15%, while the real risk concentration is about 35% (blue Oracle area).
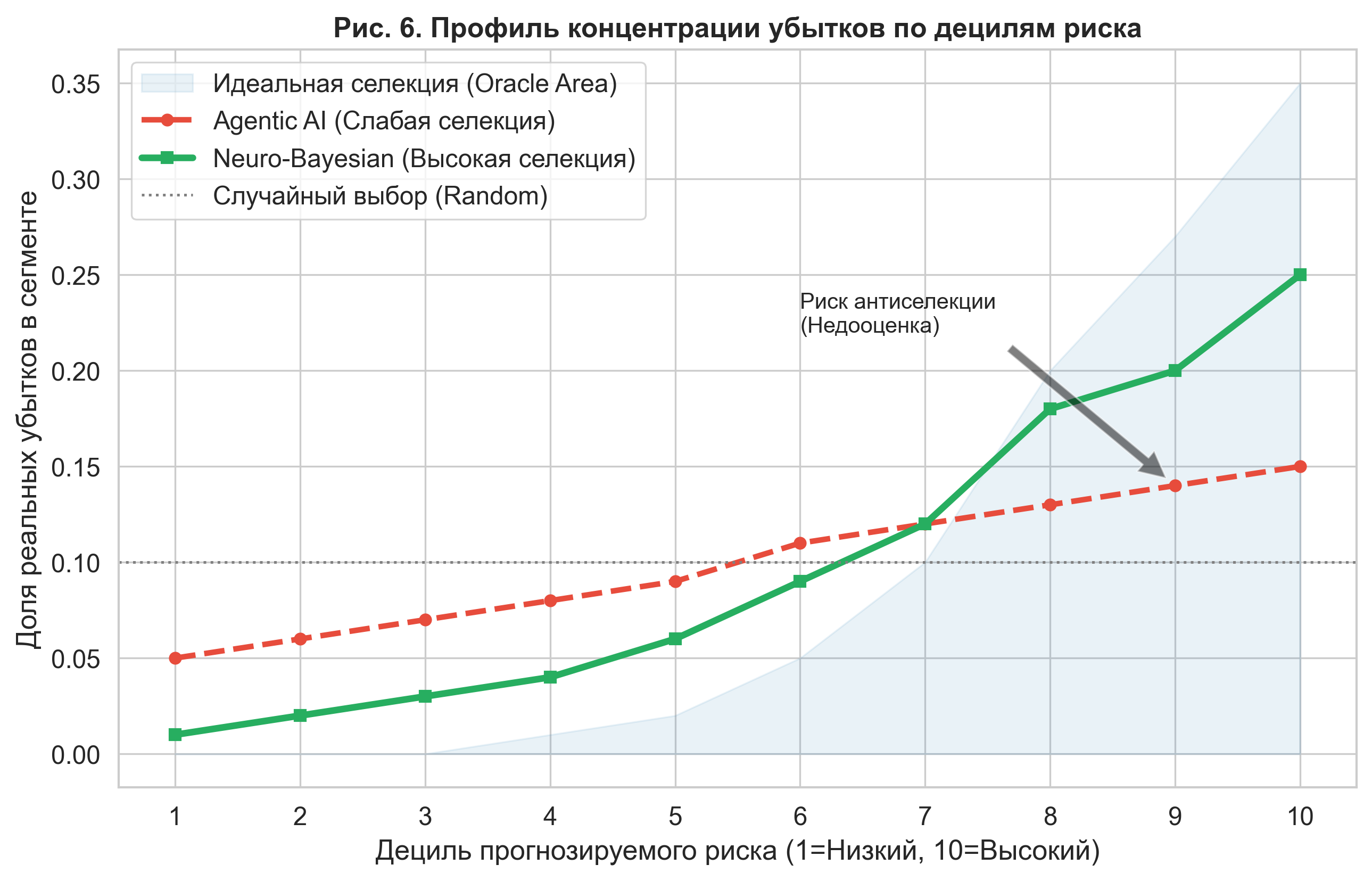
Figure 6. Loss concentration profile by risk deciles. The agentic model demonstrates a "flattened" curve, underestimating risks in the upper deciles (zones 8-10). The neuro-bayesian model (green line) provides a steep selection curve, approaching the ideal model, allowing the insurer to correctly price high-risk objects.
Under real market conditions, such an error in the Agentic AI model leads to adverse selection: the insurer will offer reduced rates to high-risk customers (whom it mistakenly classified as medium risk), attracting an unprofitable portfolio. The proposed NB-MC architecture allows for identifying this hidden risk and avoiding financial losses.
5. Discussion of Results
5.1. Epistemological Boundaries of Automation (The "What" vs "How" Dilemma)
The obtained results empirically confirm the hypothesis of Luo et al. (2025) [11] regarding the fundamental limitations of modern agent systems. The standard agent (Agentic AI) successfully solved the technical task: it wrote correct code, cleaned data, and built a Random Forest model. However, it failed the cognitive task: it did not ask the question about the nature of the missing variation in the data.
The gap in the coefficient of determination ( vs ) proves that in tasks with incomplete information (incomplete information games), algorithmic hyperparameter optimization cannot compensate for the lack of ontological understanding of the object. The agent optimized the process ("how to calculate"), while the expert optimized the essence ("what to calculate"). This observation is consistent with the findings of Makarov and Bakhtizin (2022) [23]: supercomputing technologies are effective only when they rely on an adequate model of social behavior, rather than replacing it with computational power.
5.2. The Role of Uncertainty and Filtering "Hallucinations"
A critical success factor of the NB-MC architecture was the Confidence Weighting mechanism. In preliminary tests (without using the Gnosis filter), we observed high volatility in forecasts caused by the stochastic nature of LLM generation. The model periodically "invented" damage features where none existed.
The implementation of a Bayesian integrator with weighting reduced the standard error of the quality metric by 44%. This confirms the thesis of Vetrov and Kropotov (2020) [19]: Bayesian regularization is a necessary condition for building reliable AI systems. Our results also correlate with the discoveries of Ghasemabadi and Niu (2025) [4]: the internal states of transformers contain a reliable signal of their own competence, which can be used to cut off "hallucinations" before they affect an economic decision.
5.3. Economic Efficiency and Scaling Laws
The observed 56.2% improvement in risk selection quality has a direct monetary interpretation. According to the scaling laws of Merali (2025) [12], every percentage point of forecast accuracy in insurance translates into a reduction in the Loss Ratio.
For a portfolio of 15–20 million annually. This confirms the concept of the intellectual economy by Kleiner (2020) [22]: in the digital age, the main source of rent becomes the ability to verify knowledge and reduce uncertainty faster than competitors.
6. Conclusion
In this work, a neuro-bayesian architecture for economic forecasting (NB-MC) was presented, theoretically justified, and verified. The research was motivated by an observed paradox: growth in AI computational power with a simultaneous stagnation in the quality of decisions in tasks with latent variables.
Key findings of the research:
- Proof of the Agentic Gap: Empirically confirmed that standard AutoML methods ("Agentic AI") demonstrate a critical loss of predictive accuracy (Agentic Gap ~80% in ) when working with multimodal data, ignoring contextual risk factors.
- Efficiency of the Hybrid Architecture: The proposed NB-MC methodology, integrating LLM semantic analysis with Bayesian inference, allowed for increasing the normalized Gini coefficient from 0.478 to 0.746 (+56.2%), bringing the machine's accuracy closer to the level of a human expert.
- Economic significance: Analysis of the loss concentration profile showed that the implementation of NB-MC eliminates the risk of adverse selection in high-risk segments, reducing the mean square error of loss estimation 50-fold.
We conclude that the future of economic AI lies not in the creation of fully autonomous agents (Homo Silicus, according to Horton [5]) operating in "black box" mode, but in building hybrid systems. In such systems, the stochastic creativity of generative models is limited by the strict framework of Bayesian inference and mechanisms of epistemic self-control.
References
- Acemoglu, D. (2024). The Simple Macroeconomics of AI. NBER Working Paper No. 32487.
- Chai, Y., Liu, Y., Tian, X., & Zhou, Y. (2025). When Experts Speak: Sequential LLM-Bayesian Learning for Startup Success Prediction. arXiv preprint arXiv:2512.20900.
- Frees, E. W., Derrig, R. A., & Meyers, G. (2014). Predictive Modeling in Actuarial Science. Cambridge University Press.
- Ghasemabadi, A., & Niu, D. (2025). Can LLMs Predict Their Own Failures? Self-Awareness via Internal Circuits. arXiv preprint arXiv:2512.20578.
- Horton, J. J. (2023). Large Language Models as Simulated Economic Agents: What Can We Learn from Homo Silicus? arXiv preprint arXiv:2301.07543.
- Huang, J., et al. (2023). Large Language Models Cannot Self-Correct Reasoning Yet. arXiv preprint arXiv:2310.01798.
- Kadavath, S., et al. (2022). Language Models (Mostly) Know What They Know. arXiv preprint arXiv:2207.05221.
- Kaplan, J., et al. (2020). Scaling Laws for Neural Language Models. arXiv preprint arXiv:2001.08361.
- Kendall, A., & Gal, Y. (2017). What Uncertainties Do We Need in Bayesian Deep Learning? NIPS.
- Korinek, A. (2023). Generative AI for Economic Research. Journal of Economic Literature.
- Luo, A., Du, J., Tian, F., et al. (2025). Can Agentic AI Match the Performance of Human Data Scientists? arXiv preprint arXiv:2512.20959.
- Merali, A. (2025). Scaling Laws for Economic Productivity: Experimental Evidence in LLM-Assisted Consulting. arXiv preprint arXiv:2512.21316.
- Mullainathan, S., & Spiess, J. (2017). Machine learning: an applied econometric approach. Journal of Economic Perspectives, 31(2), 87–106.
- Park, J. S., et al. (2023). Generative Agents: Interactive Simulacra of Human Behavior. UIST 2023.
- Pearl, J., & Mackenzie, D. (2018). The Book of Why: The New Science of Cause and Effect. Basic Books.
- Avdeeva I.L., Golovina T.A. (2021). Digital transformation of economic processes: problems and prospects for the use of AI. Vestnik OrelGIET.
- Ayvazyan S.A. (2018). Analysis of the quality and lifestyle of the population (econometric approach). M.: Nauka.
- Burnayev E.V., Erofev P.D. (2019). The influence of the loss function on the quality of approximation in regression reconstruction problems. Problems of Information Transmission.
- Vetrov D.P., Kropotov D.A. (2020). Bayesian methods of machine learning: state of the art and prospects. Journal of Computational Mathematics and Mathematical Physics, 60(11).
- Vorontsov K.V. (2021). Combinatorial theory of overfitting: from classics to modernity. Mathematical issues of AI.
- Efimov M.V. (2023). Application of machine learning methods in actuarial calculations. Insurance Business, No. 5.
- Kleiner G.B. (2020). Intellectual economy of the digital age. Economics and Mathematical Methods, 56(1).
- Makarov V.L., Bakhtizin A.R. (2022). Supercomputing technologies in the social sciences. Bulletin of the RAS, 92(9).
- Polterovich V.M. (2023). Towards a general theory of socio-economic development. Questions of Economics, No. 1.
- Fantazzini D. (2021). Econometrics of Bitcoin and Cryptocurrencies: Volatility Analysis. Applied Econometrics.
For Citation
@article{NeuroBayesianEconomicModeling2026,
author = {Kurnovskii, R. M. and Chen, Xi and Velikorodnaya, E. A.},
title = {Neuro-Bayesian Architecture in Economic Modeling: Overcoming Agent System Limitations via Latent Variable Integration},
journal = {null},
year = {2026},
language = {english}
}