EVOLUTION OF MACHINE LEARNING METHODS: FROM ALPHAZERO TO ALPHAPROOF AND THEIR APPLICATION IN SOLVING MATHEMATICAL PROBLEMS
Kurnovskii R.M.
Abstract:
This paper provides a detailed account of the machine learning algorithms that underpin the AlphaZero system, together with an analysis of their application to the resolution of complex mathematical problems in the AlphaProof system. The objective of this paper is to identify the mathematical principles underlying the algorithms that make them so effective. Furthermore, the paper investigates the potential and obstacles to utilizing neural networks in scientific enquiry, particularly within the domain of mathematical proofs. To this end, a comprehensive review of the scientific literature and systematic organization of the research data were carried out. It was determined that the efficacy of the models was contingent upon optimizations of Monte Carlo tree search algorithms and the development of novel methodologies. AlphaProof employs reinforcement learning techniques derived from AlphaZero, which was initially deployed in games such as chess and Go. These techniques enable the system to address mathematical problems of considerable complexity. By transforming over a million problems from diverse domains, including algebra, number theory, and geometry, into formal languages like Lean, AlphaProof can efficiently generate and verify solutions, making it a valuable tool for mathematical research.
Keywords: machine learning, neural networks, mathematical problems, AlphaZero, AlphaProof
Introduction
On July 25, 2024, the Google DeepMind Research team, which focuses on developing and applying machine learning methods to solve mathematical problems, announced that their latest models, AlphaProof and AlphaGeometry 2, were able to solve problems from the highly complex 65th International Mathematical Olympiad (IMO 2024) at the level of a silver medalist, falling short of the gold medal threshold by just 1 point [1]. It is worth noting that, unlike human participants who have 4.5 hours to solve the problems, the neural networks took 3 days. Despite this, a manifold acceleration of AlphaProof's performance is expected in the near future. The rapid growth of neural networks across various applied and fundamental fields over the past few years has drawn the attention of many experts. One of the critical questions is the evolution and development of training methods.
The purpose of this work is to determine the key technical and mathematical features of the algorithms used by AlphaZero, AlphaProof, and similar models, which allow them to solve mathematical problems so successfully.
Materials and Methods
To conduct this research, a systematic assessment and analysis of scientific publications dedicated to the evolution of machine learning methods was carried out, with a specific focus on the development and application of models like AlphaZero and AlphaProof in solving mathematical problems. The primary research method was a literature review, encompassing the search, selection, classification, and critical analysis of scientific articles published between 2012 and 2024. Materials for analysis were sourced from international scientific journals, including Nature, IEEE, and Science, as well as publications from Google DeepMind. The search keywords included: AlphaZero, AlphaProof, "machine learning", "solving mathematical problems", and "deep learning". Articles detailing both the technical aspects of the algorithms and their applicability in mathematics and related fields were reviewed. The selection criteria included the relevance of the research to the application of machine learning methods for mathematical problems and detailed descriptions of the AlphaZero and AlphaProof architectures. The PRISMA methodology was used to structure the data, enabling the systematization of the search process, the exclusion of duplicate data, and the rigorous analysis of relevant sources.
Results and Discussion
All notations and symbols used in the mathematical descriptions are provided in the table below.
Notations Used
| Symbol | Description |
|---|---|
| p | A vector, each component of which () is the probability of taking this position for a given action |
| v | A scalar evaluating the expected result |
| Neural network hyperparameters | |
| Neural network function given the hyperparameters | |
| s | Current position on the board (e.g., in the game of Go) |
| a | Transition made along the tree (action) |
| Pr(a|s) | Probability of occupying a given position on the board for a given action |
| z | A scalar characterizing the actual game result |
| Probability vector of making a given transition along the tree from a given initial position | |
| A scalar evaluating the game result at a given step | |
| l | Loss function in the gradient descent method |
| T | A scalar characterizing the final position on the tree |
| c | Regularization parameter |
| A scalar determining the exploration level of a given tree branch | |
| x | Loss function error parameter distinguishing the PBT algorithm from the AlphaZero algorithm |
All solutions belonging to DeepMind's Alpha family—which includes AlphaFold 2, AlphaZero, AlphaGo, AlphaStar, AlphaTensor, AlphaCode, and others—are aimed at solving applied and scientific computational problems. The AlphaProof system under review is a reinforcement learning AlphaZero model pre-trained on a large dataset of mathematical problems and their solutions. Its workflow is illustrated in Figure 1.
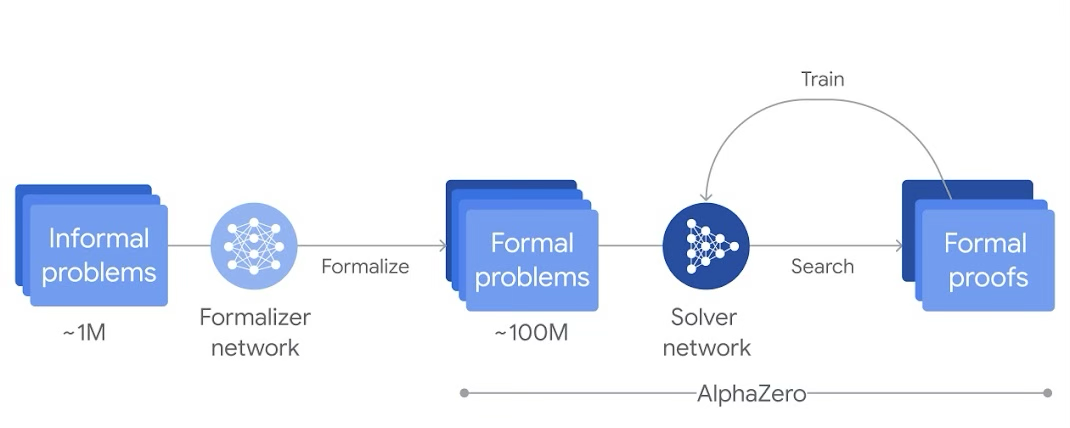 Over a million handwritten mathematical problems covering all areas of geometry, algebra, probability theory, number theory, mathematical analysis, and others were translated into the formal language Lean using Gemini [1]. This approach resolved the majority of issues associated with natural language processing, neural network hallucinations, and contextual errors. For geometry problems, the AlphaGeometry model was significantly improved by increasing the volume of training problems.
Over a million handwritten mathematical problems covering all areas of geometry, algebra, probability theory, number theory, mathematical analysis, and others were translated into the formal language Lean using Gemini [1]. This approach resolved the majority of issues associated with natural language processing, neural network hallucinations, and contextual errors. For geometry problems, the AlphaGeometry model was significantly improved by increasing the volume of training problems.
AlphaZero is a neural network that learns by competing against itself over many millions of reinforcement attempts. Initially, the learning process is random, but the neural network rapidly learns to adjust its parameters, doing so much more successfully than models trained on pre-prepared data. AlphaZero utilizes a heuristic Monte Carlo Tree Search (MCTS) algorithm combined with node evaluation using deep learning functions. This neural network-based node evaluation is what distinguishes the algorithm from classic MCTS. The network is first trained to predict subsequent data based on past data (SL-policy network), then it is trained by playing against itself (RL-policy network), and finally, it learns to predict winning chances [2]. Ultimately, this method relies on the mathematical foundations of decision theory (Markov decision processes and their Partially Observable extensions), game theory, combinatorics, the Monte Carlo method, and artificial intelligence in real games.
The MCTS algorithm iteratively builds a decision search tree until a specific limit regarding memory, time, or accuracy is reached. Similar to many other tree search algorithms, the iterations are performed in four steps: selection of child nodes, expansion of nodes, simulation, and backpropagation of error statistics [3]. An illustration of the algorithm is shown in Figure 2.
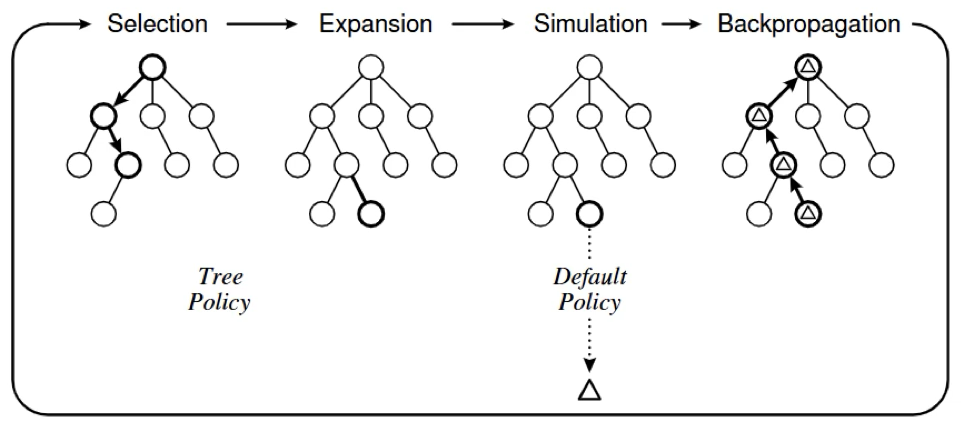
Let us consider the mathematical foundations of the AlphaZero algorithms. Note that bold symbols indicate vector quantities unless otherwise specified.
The authors of AlphaZero in [4] describe the applied deep neural network as a function with parameters . Taking the game of Go as an example, the neural network receives the current board position , and outputs a probability vector for each action , alongside a scalar estimating the expected game result. The mathematical model is expressed as:
Where:
p— action probability vector:v— estimated game result :
The parameters are adjusted during training through self-play matches generated via reinforcement learning. In each game starting from an initial position , a vector is returned during the branch search. The neural network's parameters are constantly updated to minimize the difference between the predicted game result and the actual result . To achieve this, parameters are adjusted using gradient descent on the loss function :
Where:
T— final position on the treec— regularization parameter
In AlphaZero, much like in AlphaGo Zero, Bayesian optimization is utilized for hyperparameters, but these, along with the network and general algorithm settings, remain fixed from game to game [5]. Each edge in the search tree stores a specific set of statistical data:
Where:
- — prior probability
- — visit count
- — action value
- — total action value
Each simulation starts from the initial state and iteratively selects moves that maximize the upper confidence bound defined as:
specifically, the PUCT algorithm proposes the following form for the function :
where is a constant determining the exploration level of the given branch.
As the algorithm traverses an edge , the counter is updated, and is adjusted according to the rule:
Beyond the simplified mathematical explanation of AlphaZero provided above, the complete mathematical model includes numerous probabilistic corrections and intricate, step-by-step adjustments.
Following the publication of the AlphaZero papers, multiple research teams—both within DeepMind and externally—began exploring optimization methods for the AlphaZero algorithms. In 2020, researchers in [6] proposed their proprietary "Population Based Training" (PBT) method. They adapted approaches conventionally used in machine learning for processing genetic data, deploying multiple neural networks with random initial parameters ![][image4]. These networks pool information to enhance hyperparameters. If a network's parameters are suboptimal, they are directly replaced by the superior hyperparameters from a better-performing neural network. It is also worth noting that the algorithm allows for manual hyperparameter adjustments for research purposes.
In that specific study, 16 neural networks were utilized for evaluations, and the loss function was modified to depend on an error parameter mapping the difference between and :
The authors discovered that by applying the PBT method to Go on a board, the win rate against Facebook's ELF OpenGo v2—a neural network closely matching the power of open AlphaZero implementations—reached 74%. This demonstrates that the innovative application of varied approaches in neural network training holds significant potential to enhance the capabilities of such competitive systems.
AlphaProof relies on data pre-processed by Gemini, consisting of mathematical problems formalized in Lean. This translation process represents a bottleneck in the technology and highlights the inherent flaws of training models purely on natural language, making it currently impossible to completely avoid distortions. To solve a specific mathematical problem, AlphaProof must first formalize it. Then, following the AlphaZero algorithm described above, hundreds of candidate solutions are generated. These solutions are subsequently verified using Lean. If a solution is deemed incorrect, the system evaluates the next candidate, repeating the process until the correct solution is found. This rigorous verification is made possible because Lean is a functional programming language with dependent types based on the Calculus of Constructions (CoC) and the Calculus of Inductive Constructions (CiC) [7]. Furthermore, the Lean 4 version supports high-performance memory management technologies, significantly streamlining the training process for complex systems like AlphaProof.
To date, there are no published benchmarks detailing the complete results of the AlphaProof system's algorithms. It remains unclear whether its accuracy and speed vary depending on the specific mathematical subfield of the problems. Furthermore, Google DeepMind has yet to release detailed data regarding the intermediate training stages, the speed of training across different tasks, or whether specific adjustments to the training method were necessary. This data is anticipated in the near future alongside the release of the system's second version. However, it is already evident that the application of neural networks will become a substantial and vital component in the future development of mathematics. It will enable the rigorous verification of the most complex and extensive theorems with high precision and speed, including proofs in highly abstract areas of mathematics currently beyond the reach of existing AI models. Beyond proving theorems, this will act as a major breakthrough for both solving and generating highly difficult mathematical problems. Terence Tao, one of the world's leading mathematicians, spoke at The Oxford Mathematics Public Lectures about the profound impact such neural networks will have on the future of mathematics, identifying them as indispensable tools and true collaborators in mathematical research.
Conclusion
All the evidence presented above suggests that significant progress in machine learning methods, along with the refinement and broadened application of AlphaZero in both applied and fundamental research, will only accelerate. AlphaProof, in turn, demonstrates immense potential as a powerful tool for scientists, reflecting the continuous progress in optimizing and advancing the algorithms driving these intelligent systems.
References
- AI achieves silver-medal standard solving International Mathematical Olympiad problems // Google DeepMind. [Online resource]. URL: https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/ (accessed: 04.09.2024).
- David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam. Marc Lanctot. Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, Demis Hassabis. Mastering the game of Go with deep neural networks and tree search // Nature. 2016. Vol. 529, Is. 7587. P. 484–489.
- Cameron B. Browne, Edward Powley, Daniel Whitehouse, Simon M. Lucas, Peter I. Cowling, Philipp Rohlfshagen. A Survey of Monte Carlo Tree Search Methods // IEEE Trans. Comput. Intell. AI Games. 2012, Vol. 4, Is. 1. P. 1–43.
- David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, Demis Hassabis. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play // Science. 2018. Vol. 362, Is. 6419. P. 1140–1144.
- David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel & Demis Hassabis. Mastering the game of Go without human knowledge // Nature. 2017. Vol. 550, Is. 7676. P. 354–359.
- Ti-Rong Wu, Ting-Han Wei, I-Chen Wu. Accelerating and Improving AlphaZero Using Population Based Training. The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20). 2020. P. 1046–1053.
- About Lean // Lean. [Online resource]. URL: https://lean-lang.org/about/ (accessed: 04.09.2024).
For Citation
@article{AlphaZero2AlphaProofEvolution,
author = {Kurnovskii, R. M.},
title = {Evolution of Machine Learning Methods: From AlphaZero to AlphaProof and Their Application in Solving Mathematical Problems},
journal = {International Journal of Applied and Fundamental Research},
number = {12},
year = {2024},
pages = {41--45},
language = {english},
annote = {This article examines in detail the machine learning algorithms underlying the AlphaZero system, as well as their application for solving complex mathematical problems in the AlphaProof system. The aim of the work was to determine the mathematical rules of the algorithms that make them so effective. The article also discusses the prospects and challenges associated with the use of neural networks in scientific research, especially in the field of mathematical proofs. For this purpose, a comprehensive review of scientific sources and systematization of research data was conducted. It was found that the effectiveness of the models was associated with optimizations of Monte Carlo tree search algorithms and the development of new methods. AlphaProof uses reinforcement learning methods developed on the basis of AlphaZero, which was originally used for games such as chess and Go. These methods allow the system to handle mathematical problems of high complexity. By converting more than a million problems from various fields, including algebra, number theory, and geometry, into formal languages such as Lean, AlphaProof effectively generates and checks solutions, making it a powerful tool for mathematical research.}
}